The Quick Python Book
Part 3: Advanced language features
The previous chapters have been a survey of the basic features of Python: the features that most programmers will use most of the time. What follows is a look at some more advanced features, such as how classes and objects work in Python, regular expressions, packages, and the standard library. While you may not use these every day (depending on your needs), knowledge of these topics is vital when you need them.
15. Classes and object-oriented programming
This chapter covers
- Defining classes
- Using instance variables and @property
- Defining methods
- Defining class variables and methods
- Inheriting from other classes
- Making variables and methods private
- Inheriting from multiple classes
In this chapter, I discuss Python classes, which can be used to hold both data and code. Although most programmers are probably familiar with classes or objects in other languages, I make no particular assumptions about knowledge of a specific language or paradigm. In addition, this chapter is a description only of the constructs available in Python; it’s not an exposition on object-oriented programming (OOP) itself.
15.1 Defining classes
A class in Python is effectively a data type. All the data types built into Python are classes, and Python gives you powerful tools to manipulate every aspect of a class’s behavior. You define a class with the class statement:
class MyClass:
bodybody is a list of Python statements—typically, variable assignments and function definitions. No assignments or function definitions are required. The body can be just a single pass statement.
By convention, class identifiers are in CapCase—that is, the first letter of each component word is capitalized, to make the identifiers stand out. After you define the class, you can create a new object of the class type (an instance of the class) by calling the class name as a function:
instance = MyClass()15.1.1 Using a class instance as a structure or record
Class instances can be used as structures or records. Unlike C structures or Java classes, the data fields of an instance don’t need to be declared ahead of time; they can be created on the fly. The following short example defines a class called Circle, creates a Circle instance, assigns a value to the radius field of the circle, and then uses that field to calculate the circumference of the circle:
class Circle:
pass
my_circle = Circle()
my_circle.radius = 5
print(2 * 3.14 * my_circle.radius)
#> 31.4As in Java and many other languages, the fields of an instance/structure are accessed and assigned to by using dot notation.
You can initialize fields of an instance automatically by including an __init__ initialization method in the class body. This function is run every time an instance of the class is created, with that new instance as its first argument, self. The __init__ method is similar to a constructor in Java, but it doesn’t really construct anything; it initializes fields of the class. Also, unlike those in Java and C++, Python classes may only have one __init__ method. This example creates circles with a radius of 1 by default:
class Circle:
def __init__(self): # <-- self as parameter for __init__()
self.radius = 1
my_circle = Circle() # <-- Creates instance of Circle
print(2 * 3.14 * my_circle.radius) # <-- radius field already set
my_circle.radius = 5 # <-- Overwriting radius
print(2 * 3.14 * my_circle.radius) # <-- Different result with different radius
#> 6.28
#> 31.400000000000002By convention, self is always the name of the first argument of __init__. self is set to the newly created circle instance when __init__ is run. Next, the code uses the class definition. You first create a Circle instance object. The next line makes use of the fact that the radius field is already initialized. You can also overwrite the radius field; as a result, the last line prints a different result from the previous print statement.
Python also has something more like a constructor: the __new__ method, which is what is called on object creation and returns an uninitialized object. Unless you’re subclassing an immutable type, like str or int, or using a metaclass to modify the object creation process, it’s rare to override the existing __new__ method.
You can do a great deal more by using true OOP, and if you’re not familiar with it, I urge you to read up on it. Python’s OOP constructs are the subject of the remainder of this chapter.
15.2 Instance variables
Instance variables are the most basic feature of OOP. Take a look at the Circle class again:
class Circle:
def __init__(self):
self.radius = 1radius is an instance variable of Circle instances. That is, each instance of the Circle class has its own copy of radius, and the value stored in that copy may be different from the values stored in the radius variable in other instances. In Python, you can create instance variables as necessary by assigning to a field of a class instance:
instance.variable = valueIf the variable doesn’t already exist, it’s created automatically, which is how __init__ creates the radius variable.
All uses of instance variables, both assignment and access, require explicit mention of the containing instance—that is, instance.variable. A reference to variable by itself is a reference not to an instance variable but to a local variable in the executing method. This is different from C++ and Java, where instance variables are referred to in the same manner as local method function variables. I rather like Python’s requirement for explicit mention of the containing instance because it clearly distinguishes instance variables from local function variables.
What code would you use to create a Rectangle class?
15.3 Methods
A method is a function associated with a particular class. You’ve already seen the special __init__ method, which is called on a new instance when that instance is created. In the following example, you define another method, area, for the Circle class; this method can be used to calculate and return the area for any Circle instance. Like most user-defined methods, area is called with a method invocation syntax that resembles instance variable access:
class Circle:
def __init__(self):
self.radius = 1
def area(self):
return self.radius * self.radius * 3.14159
c = Circle()
c.radius = 3
print(c.area())
#> 28.27431Method invocation syntax consists of an instance, followed by a period, followed by the method to be invoked on the instance. When a method is called in this way, it’s a bound method invocation. However, a method can also be invoked as an unbound method by accessing it through its containing class. This practice is less convenient and is almost never done, because when a method is invoked in this manner, its first argument must be an instance of the class in which that method is defined and is less clear:
print(Circle.area(c))
#> 28.27431Like __init__, the area method is defined as a function within the body of the class definition. The first argument of any method is the instance it was invoked by or on, named self by convention. In many languages the instance, often called this, is implicit and is never explicitly passed, but Python’s design philosophy prefers to make things explicit.
Methods can be invoked with arguments if the method definitions accept those arguments. This version of Circle adds an argument to the __init__ method so that you can create circles of a given radius without needing to set the radius after a circle is created:
class Circle:
def __init__(self, radius):
self.radius = radius
def area(self):
return self.radius * self.radius * 3.14159Note the two uses of radius here. self.radius is the instance variable called radius; radius by itself is the local function parameter called radius. The two aren’t the same! In practice, you’d probably call the local function parameter something like r or rad to avoid any possibility of confusion.
Using this definition of Circle, you can create circles of any radius with one call on the Circle class. The following creates a Circle of radius 5:
c = Circle(5)All the standard Python function features—default argument values, extra arguments, keyword arguments, and so forth—can be used with methods. You could have defined the first line of __init__ to be
def __init__(self, radius=1):Then calls to circle would work with or without an extra argument; Circle() would return a circle of radius 1, and Circle(3) would return a circle of radius 3.
There’s nothing magical about method invocation in Python, which can be considered shorthand for normal function invocation. Given a method invocation instance .method(arg1, arg2, . . .), Python transforms it into a normal function call by using the following rules:
- Look for the method name in the instance namespace. If a method has been changed or added for this instance, it’s invoked in preference over methods in the class or superclass. This lookup is the same sort of lookup discussed in section 15.4.1 later in this chapter.
- If the method isn’t found in the instance namespace, look up the class type class of instance, and look for the method there. In the previous examples, class is Circle—the type of the instance c.
- If the method still isn’t found, look for the method in the superclasses.
- When the method has been found, make a direct call to it as a normal Python function, using the instance as the first argument of the function and shifting all the other arguments in the method invocation one space over to the right. So instance.method(arg1, arg2, . . .) becomes class.method (instance, arg1, arg2, . . .).
Update the code for a Rectangle class so that you can set the dimensions when an instance is created, just as for the Circle class previously. Also, add an area() method.
15.4 Class variables
A class variable is a variable associated with a class, not an instance of a class, and is accessible by all instances of the class. A class variable might be used to keep track of some class-level information, such as how many instances of the class have been created at any point. Python provides class variables, although using them requires slightly more effort than in most other languages. Also, you need to watch out for an interaction between class and instance variables.
A class variable is created by an assignment in the class body, not in the __init__ function. After it has been created, it can be seen by all instances of the class. You can use a class variable to make a value for pi accessible to all instances of the Circle class:
class Circle:
pi = 3.14159
def __init__(self, radius):
self.radius = radius
def area(self):
return self.radius * self.radius * Circle.piWith the definition entered, you can type
Circle.pi
#> 3.14159Circle.pi = 4
Circle.pi
#> 4Circle.pi = 3.14159
Circle.pi
#> 3.14159This example is exactly how you’d expect a class variable to act; it’s associated with and contained in the class that defines it. Notice in this example that you’re accessing Circle.pi before any circle instances have been created. Obviously, Circle.pi exists independently of any specific instances of the Circle class.
You can also access a class variable from a method of a class, through the class name. You do so in the definition of Circle.area, where the area function makes specific reference to Circle.pi. In operation, this has the desired effect; the correct value for pi is obtained from the class and used in the calculation:
c = Circle(3)
c.area()
#> 28.27431You may object to hardcoding the name of a class inside that class’s methods. You can avoid doing so through use of the special __class__ attribute, available to all Python class instances. This attribute returns the class of which the instance is a member—for example:
Circle
#> <class '__main__.Circle'>
c.__class__
#> <class '__main__.Circle'>The class named Circle is represented internally by an abstract data structure, and that data structure is exactly what is obtained from the __class__ attribute of c, an instance of the Circle class. This example lets you obtain the value of Circle.pi from c without ever explicitly referring to the Circle class name:
c.__class__.pi
#> 3.14159You could use this code internally in the area method to get rid of the explicit reference to the Circle class; replace Circle.pi with self.__class__.pi.
15.4.1 An oddity with class variables
There’s a bit of an oddity with class variables that can trip you up if you aren’t aware of it. When Python is looking up an instance variable, if it can’t find an instance variable of that name, it tries to find and return the value in a class variable of the same name. Only if it can’t find an appropriate class variable will Python signal an error. Class variables make it efficient to implement default values for instance variables; just create a class variable with the same name and appropriate default value and avoid the time and memory overhead of initializing that instance variable every time a class instance is created. But this also makes it easy to inadvertently refer to an instance variable rather than a class variable without signaling an error. In this section, I look at how class variables operate in conjunction with the previous example.
First, you can refer to the variable c.pi, even though c doesn’t have an associated instance variable named pi. Python first tries to look for such an instance variable; when it can’t find an instance variable, Python looks for and finds a class variable pi in Circle:
c = Circle(3)
c.pi
#> 3.14159This result may or may not be what you want. This technique is convenient but can be prone to error, so be careful.
Now, what happens if you attempt to use c.pi as a true class variable by changing it from one instance with the intention that all instances should see the change? Again, you use the earlier definition for Circle:
c1 = Circle(1)
c2 = Circle(2)
c1.pi = 3.14
c1.pi
#> 3.14
c2.pi
#> 3.14159
Circle.pi
#> 3.14159This example doesn’t work as it would for a true class variable; c1 now has its own copy of pi, distinct from the Circle.pi accessed by c2. This happens because the assignment to c1.pi creates an instance variable in c1; it doesn’t affect the class variable Circle.pi in any way. Subsequent lookups of c1.pi return the value in that instance variable, whereas subsequent lookups of c2.pi look for an instance variable pi in c2, fail to find it, and resort to returning the value of the class variable Circle.pi. If you want to change the value of a class variable, access it through the class name, not through the instance variable self.
15.5 Static methods and class methods
Python classes can also have methods that correspond explicitly to static methods in a language such as Java. In addition, Python has class methods, which are a bit more advanced.
15.5.1 Static methods
Just as in Java, you can invoke static methods even though no instance of that class has been created, although you can call them by using a class instance. To create a static method, use the @staticmethod decorator, as shown in the following listing.
Listing 15.1 File circle.py
"""circle module: contains the Circle class."""
class Circle:
"""Circle class"""
all_circles = [] # <-- Class variable containing list of all circles that have been created
pi = 3.14159
def __init__(self, r=1):
"""Create a Circle with the given radius"""
self.radius = r
self.__class__.all_circles.append(self) # <-- When an instance isinitialized, it adds itself to the all_circles list.
def area(self):
"""determine the area of the Circle"""
return self.__class__.pi * self.radius * self.radius
@staticmethod
def total_area():
"""Static method to total the areas of all Circles """
total = 0
for c in Circle.all_circles: # c: each instance of Circle
total = total + c.area() # c.area(): the area of the circle
return totalNow interactively type the following:
import circle
c1 = circle.Circle(1)
c2 = circle.Circle(2)
circle.Circle.total_area()
#> 15.70795
c2.radius = 3
circle.Circle.total_area()
#> 31.415899999999997Also notice that documentation strings are used. In a real module, you’d probably put in more informative strings, indicating in the class docstring what methods are available and including usage information in the method docstrings:
circle.__doc__
#> 'circle module: contains the Circle class.'
circle.Circle.__doc__
#> 'Circle class'
circle.Circle.area.__doc__
#> 'determine the area of the Circle'15.5.2 Class methods
Class methods are similar to static methods in that they can be invoked before an object of the class has been instantiated or by using an instance of the class. But class methods are implicitly passed the class they belong to as their first parameter, so you can code them more simply.
Listing 15.2 File circle_cm.py
"""circle_cm module: contains the Circle class."""
class Circle:
"""Circle class"""
all_circles = [] # <-- Variable containing list of all circles that have been created
pi = 3.14159
def __init__(self, r=1):
"""Create a Circle with the given radius"""
self.radius = r
self.__class__.all_circles.append(self)
def area(self):
"""determine the area of the Circle"""
return self.__class__.pi * self.radius * self.radius
@classmethod # <-- @classmethod decorator
def total_area(cls): # <-- cls used instead of self
total = 0
for c in cls.all_circles: # <-- cls can be used in place of Circle.
total = total + c.area()
return totalimport circle_cm
c1 = circle_cm.Circle(1)
c2 = circle_cm.Circle(2)
circle_cm.Circle.total_area()
#> 15.70795
c2.radius = 3
circle_cm.Circle.total_area()
#> 31.415899999999997The @classmethod decorator is used before the method def. The class parameter is traditionally cls. You can use cls instead of Circle.
By using a class method instead of a static method, you don’t have to hardcode the class name into total_area. As a result, any subclasses of Circle can still call total_ area and refer to their own members, not those in Circle.
Write a class method similar to total_area() that returns the total circumference of all circles. Remember that the circumference of a circle is 2 times the radius times pi.
15.6 Inheritance
Inheritance in Python is easier and more flexible than inheritance in compiled languages such as Java and C++ because the dynamic nature of Python doesn’t force as many restrictions on the language.
To see how inheritance is used in Python, start with the Circle class discussed earlier in this chapter and generalize. You might want to define an additional class for squares:
class Square:
def __init__(self, side=1):
self.side = side # <-- Length of any side of squareNow, if you want to use these classes in a drawing program, they must define some sense of where on the drawing surface each instance is. You can do so by defining an x coordinate and a y coordinate in each instance:
class Square:
def __init__(self, side=1, x=0, y=0):
self.side = side
self.x = x
self.y = y
class Circle:
def __init__(self, radius=1, x=0, y=0):
self.radius = radius
self.x = x
self.y = yThis approach works but results in a good deal of repetitive code as you expand the number of shape classes, because you presumably want each shape to have this concept of position. No doubt you know where I’m going here; this situation is a standard one for using inheritance in an object-oriented language. Instead of defining the x and y variables in each shape class, you can abstract them out into a general Shape class and have each class define a specific shape inherited from that general class. In Python, that technique looks like the following:
class Shape:
def __init__(self, x, y):
self.x = x
self.y = y
class Square(Shape): # <-- Says Square inherits from Shape
def __init__(self, side=1, x=0, y=0):
super().__init__(x, y) # <-- Must call __init__ method of Shape
self.side = side
class Circle(Shape): # <-- Says Circle inherits from Shape
def __init__(self, r=1, x=0, y=0):
super().__init__(x, y) # <-- Must call __init__ method of Shape
self.radius = rThere are (generally) two requirements in using an inherited class in Python, both of which you can see in the bolded code in the Circle and Square classes. The first requirement is defining the inheritance hierarchy, which you do by giving the classes inherited from, in parentheses, immediately after the name of the class being defined with the class keyword. In the previous code, Circle and Square both inherit from Shape. The second and more subtle element is the necessity to explicitly call the __init__ method of inherited classes. Python doesn’t automatically do this for you, but you can use the super function to have Python figure out which inherited class to use. This task is accomplished in the example code by the super().__init__(x,y) lines. This code calls the Shape initialization function with the instance being initialized and the appropriate arguments. Otherwise, in the example, instances of Circle and Square wouldn’t have their x and y instance variables set.
Instead of using super, you could call Shape’s __init__ by explicitly naming the inherited class using Shape.__init__(self, x, y), which would also call the Shape initialization function with the instance being initialized. This technique wouldn’t be as flexible in the long run because it hardcodes the inherited class’s name, which could be a problem later if the design and the inheritance hierarchy change. On the other hand, the use of super can be tricky in more complex cases. Because the two methods don’t exactly mix well, clearly document whichever approach you use in your code.
Inheritance also comes into effect when you attempt to use a method that isn’t defined in the subclass or derived class but is defined in the superclass. To see this effect, define another method in the Shape class called move, which moves a shape by a given displacement. This method modifies the x and y coordinates of the shape by an amount determined by arguments to the method. The definition for Shape now becomes
class Shape:
def __init__(self, x, y):
self.x = x
self.y = y
def move(self, delta_x, delta_y):
self.x = self.x + delta_x
self.y = self.y + delta_yIf you enter this definition for Shape and the previous definitions for Circle and Square, you can engage in the following interactive session:
c = Circle(1)
c.move(3, 4)
f"c.x = {c.x}, c.y = {c.y}"
#> 'c.x = 3, c.y = 4'If you try this code in an interactive session, be sure to reenter the Circle class after the redefinition of the Shape class.
The Circle class in the example didn’t define a move method immediately within itself, but because it inherits from a class that implements move, all instances of Circle can make use of move. In more traditional OOP terms, you could say that all Python methods are virtual—that is, if a method doesn’t exist in the current class, the list of superclasses is searched for the method, and the first one found is used.
Rewrite the code for a Rectangle class to inherit from Shape. Because squares and rectangles are related, would it make sense to inherit one from the other? If so, which would be the base class, and which would inherit?
How would you write the code to add an area() method for the Square class? Should the area method be moved into the base Shape class and inherited by Circle, Square, and Rectangle? If so, what problems would result?
15.7 Inheritance with class and instance variables
Inheritance allows an instance to inherit attributes of a class. Instance variables are associated with object instances, and only one instance variable of a given name exists for a given instance.
Consider the following example. Using these class definitions,
class P:
z = "Hello"
def set_p(self):
self.x = "Class P"
def print_p(self):
print(self.x)
class C(P):
def set_c(self):
self.x = "Class C"
def print_c(self):
print(self.x)execute the following code:
c = C()
c.set_p()
c.print_p()
#> Class P
c.print_c()
#> Class P
c.set_c()
c.print_c()
#> Class C
c.print_p()
#> Class CThe object c in this example is an instance of class C. C inherits from P but c doesn’t inherit from some invisible instance of class P. It inherits methods and class variables directly from P. Because there is only one instance (c), any reference to the instance variable x in a method invocation on c must refer to c.x. This is true regardless of which class defines the method being invoked on c. As you can see, when they’re invoked on c, both set_p and print_p, defined in class P, refer to the same variable, which is referred to by set_c and print_c when they’re invoked on c.
In general, this behavior is what is desired for instance variables, because it makes sense that references to instance variables of the same name should refer to the same variable. Occasionally, somewhat different behavior is desired, which you can achieve by using private variables (see section 15.9).
Class variables are inherited, but you should take care to avoid name clashes and be aware of a generalization of the behavior you saw in the subsection on class variables. In the example, a class variable z is defined for the superclass P and can be accessed in three ways: through the instance c, through the derived class C, or directly through the superclass P:
f"{c.z=} {C.z=} {P.z=}"
#> 'c.z='Hello' C.z='Hello' P.z='Hello''But if you try setting the class variable z through the class C, a new class variable is created for the class C. This result has no effect on P’s class variable itself (as accessed through P). But future accesses through the class C or its instance c will see this new variable rather than the original:
C.z = "Bonjour"
f"{c.z=} {C.z=} {P.z=}"
#> 'c.z='Bonjour' C.z='Bonjour' P.z='Hello''Similarly, if you try setting z through the instance c, a new instance variable is created, and you end up with three different variables:
c.z = "Ciao"
f"{c.z=} {C.z=} {P.z=}"
#> 'c.z='Ciao' C.z='Bonjour' P.z='Hello''15.8 Recap: Basics of Python classes
The points I’ve discussed so far are the basics of using classes and objects in Python. Before I go any further, I’ll bring the basics together in a single example. In this section, you create a couple of classes with the features discussed earlier, and then you see how those features behave.
First, create a base class:
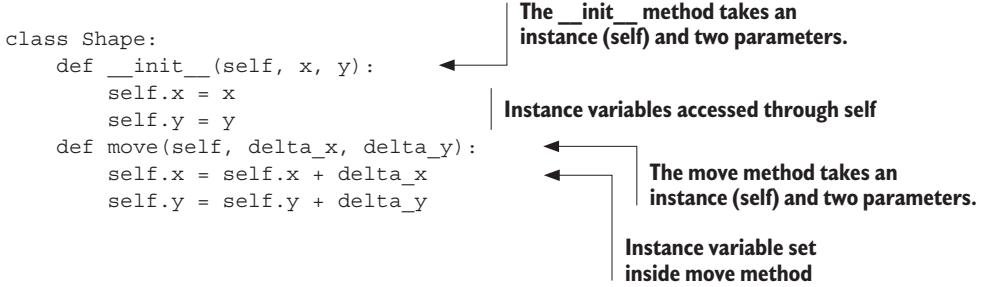
Next, create a subclass that inherits from the base class Shape:
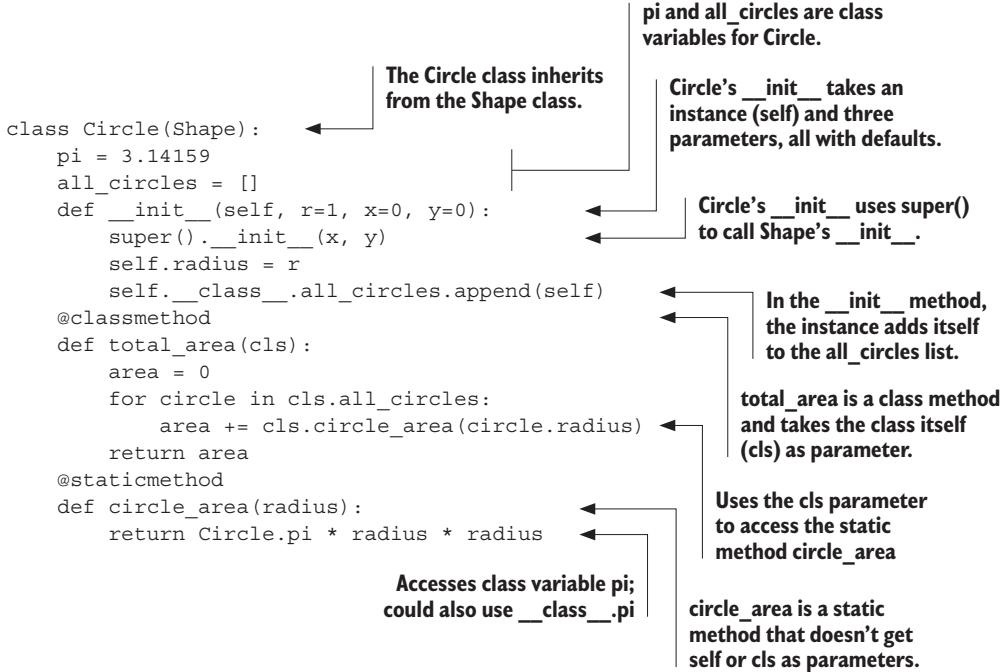
Code for the figure above
class Shape:
def __init__(self, x, y):
self.x = x
self.y = y
def move(self, delta_x, delta_y):
self.x = self.x + delta_x
self.y = self.y + delta_y
class Circle(Shape):
pi = 3.14159
all_circles = []
def __init__(self, r=1, x=0, y=0):
super().__init__(x, y)
self.radius = r
self.__class__.all_circles.append(self)
@classmethod
def total_area(cls):
area = 0
for circle in cls.all_circles:
area += cls.circle_area(circle.radius)
return area
@staticmethod
def circle_area(radius):
return Circle.pi * radius * radiusNow you can create some instances of the Circle class and put them through their paces. Because Circle’s __init__ method has default parameters, you can create a Circle without giving any parameters:
c1 = Circle()
c1.radius, c1.x, c1.y
#> (1, 0, 0)If you do give parameters, they are used to set the instance’s values:
c2 = Circle(2, 1, 1)
c2.radius, c2.x, c2.y
#> (2, 1, 1)If you call the move() method, Python doesn’t find a move() in the Circle class, so it moves up the inheritance hierarchy and uses Shape’s move() method:
c2.move(2, 2)
c2.radius, c2.x, c2.y
#> (2, 3, 3)Also, because part of what the __init__ method does is add each instance to a list that is a class variable, you get the Circle instances:
Circle.all_circles
#> [<__main__.Circle object at 0x7fa88835e9e8>, <__main__.Circle object at 0x7fa88835eb00>]
[c1, c2]
#> [<__main__.Circle object at 0x7fa88835e9e8>, <__main__.Circle object at 0x7fa88835eb00>]You can also call the Circle class’s total_area() class method, either through the class itself or through an instance:
Circle.total_area()
#> 15.70795
c2.total_area()
#> 15.70795Finally, you can call the static method circle_area(), again either via the class itself or an instance. As a static method, circle_area doesn’t get passed the instance or the class, and it behaves more like an independent function that’s inside the class’s namespace. In fact, quite often, static methods are used to bundle utility functions with a class:
Circle.circle_area(c1.radius)
#> 3.14159
c1.circle_area(c1.radius)
#> 3.14159These examples show the basic behavior of classes in Python. Now that you’ve got the basics of classes down, you can move on to more advanced topics.
15.9 Private variables and private methods
A private variable or private method is one that can’t be seen outside the methods of the class in which it’s defined. Private variables and methods are useful for two reasons: they enhance security and reliability by selectively denying access to important or delicate parts of an object’s implementation, and they prevent name clashes that can arise from the use of inheritance. A class may define a private variable and inherit from a class that defines a private variable of the same name, but this doesn’t cause a problem, because the fact that the variables are private ensures that separate copies of them are kept. Private variables make it easier to read code, because they explicitly indicate what’s used only internally in a class. Anything else is the class’s interface.
Most languages that define private variables do so through the use of the keyword “private” or something similar. The convention in Python is simpler, and it also makes it easier to immediately see what is private and what isn’t. Any method or instance variable whose name begins—but doesn’t end—with a double underscore (__) is private; anything else isn’t private.
As an example, consider the following class definition:
class Mine:
def __init__(self):
self.x = 2
self.__y = 3 # <-- Defines __y as private by using leading double underscores
def print_y(self):
print(self.__y)Using this definition, create an instance of the class:
m = Mine()x isn’t a private variable, so it’s directly accessible:
print(m.x)
#> 2__y is a private variable. Trying to access it directly raises an error:
print(m.__y)
#> AttributeError Traceback (most recent call last)
#> <ipython-input-74-c09dfe1cad43> in <cell line: 1>()
#> ----> 1 print(m.__y)
#>
#> AttributeError: 'Mine' object has no attribute '__y'The print_y method isn’t private, and because it’s in the Mine class, it can access __y and print it:
m.print_y()
#> 3Finally, you should note that the mechanism used to provide privacy mangles the name of private variables and private methods when the code is compiled to bytecode. What specifically happens is that _classname is prepended to the variable name:
dir(m)
#> ['_Mine__y',
#> ...
#> 'print_y',
#> 'x']The purpose is to prevent any accidental access. If someone wanted to, they could deliberately simulate the mangling and access the value. But performing the mangling in this easily readable form makes debugging easy.
Modify the Rectangle class’s code to make the dimension variables private. What restriction will this modification impose on using the class?
15.10 Using @property for more flexible instance variables
Python allows you as the programmer to access instance variables directly, without the extra machinery of the getter and setter methods often used in Java and other object-oriented languages. This lack of getters and setters makes writing Python classes cleaner and easier, but in some situations, using getter and setter methods can be handy. Suppose that you want a value before you put it into an instance variable or where it would be helpful to figure out an attribute’s value on the fly. In both cases, getter and setter methods would do the job—but at the cost of losing Python’s easy instance variable access.
The solution is to use a property. A property combines the ability to pass access to an instance variable through methods like getters and setters and the straightforward access to instance variables through dot notation.
To create a property, you use the property decorator with a method that has the property’s name:
class Temperature:
def __init__(self):
self._temp_fahr = 0
@property
def temp(self):
return (self._temp_fahr - 32) * 5 / 9Without a setter, such a property is read-only. To change the property, you need to add a setter:
@temp.setter
def temp(self, new_temp):
self._temp_fahr = new_temp * 9 / 5 + 32Now you can use standard dot notation to both get and set the property temp. Notice that the name of the method remains the same, but the decorator changes to the property name (temp, in this case), plus .setter indicates that a setter for the temp property is being defined:
t = Temperature()
t._temp_fahr
#> 0
t.temp # <-- The getter etter returns centigrade.
#> -17.77777777777778
t.temp = 34 # <-- The setter converts and stores in _temp_fahr.
t._temp_fahr
#> 93.2
t.temp # <-- The getter returns centigrade by converting _temp_fahr.
#> 34.0The 0 in _temp_fahr is converted to centigrade by the getter method before it’s returned, and the 34 is converted back to Fahrenheit by the setter.
One big advantage of Python’s ability to add properties is that you can do initial development with plain-old instance variables and then seamlessly change to properties whenever and wherever you need to without changing any client code. The access is still the same, using dot notation.
Update the dimensions of the Rectangle class to be properties with getters and setters that don’t allow negative sizes.
15.11 Scoping rules and namespaces for class instances
Now you have all the pieces to put together a picture of the scoping rules and namespaces for a class instance.
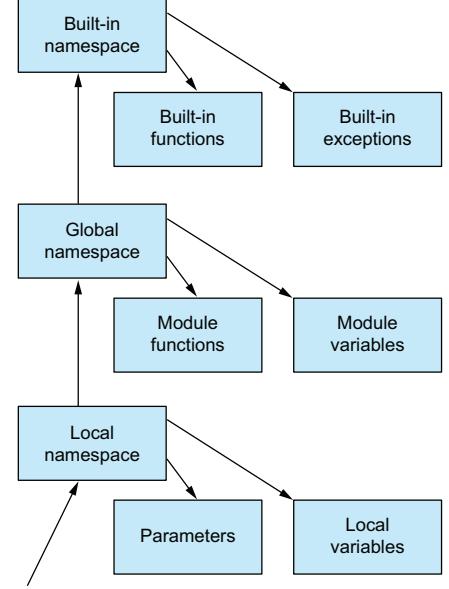
When you’re in a method of a class, you have direct access to the local namespace (parameters and variables declared in the method), the global namespace (functions and variables declared at the module level), and the built-in namespace (built-in functions and built-in exceptions). These three namespaces are searched in the following order: local, global, and built-in (see figure 15.1).
You also have access through the self variable to the instance’s namespace (instance variables, private instance variables, and superclass instance variables), its class’s namespace (methods, class variables, private methods, and private class variables), and its superclass’s namespace (superclass methods and superclass class variables). These three namespaces are searched in the order instance, class, and then superclass (see figure 15.2).
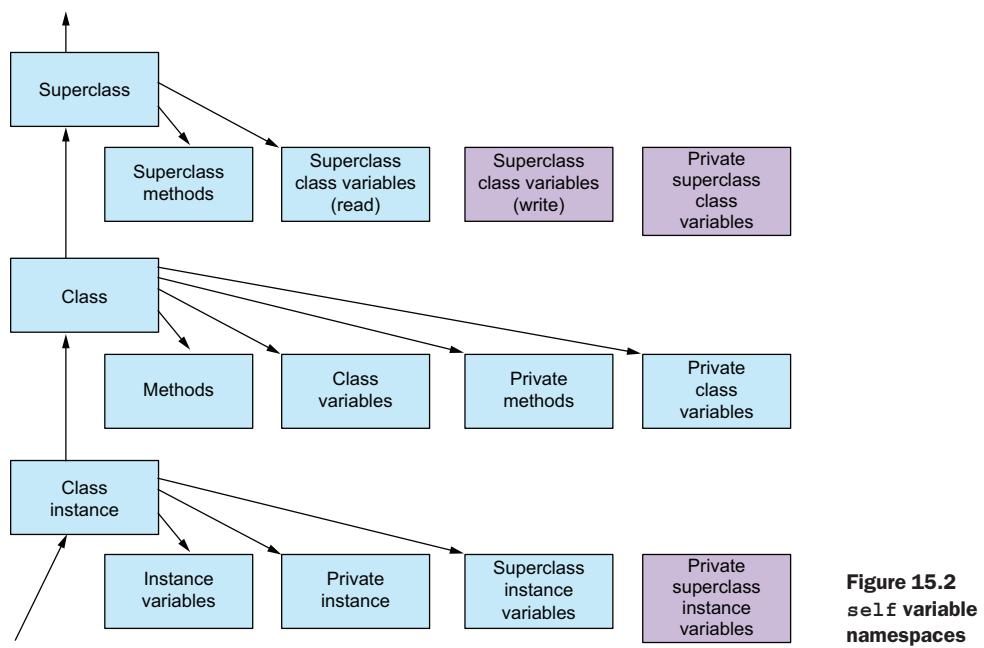
self variable namespacesPrivate superclass instance variables, private superclass methods, and private superclass class variables can’t be accessed by using self. A class is able to hide these names from its children.
The module in the following listing puts these two examples together to concretely demonstrate what can be accessed from within a method.
Listing 15.3 File cs.py
"""cs module: class scope demonstration module."""
mod_var = "module variable: mod_var"
def mod_func():
return "module level function: mod_func()"
class SuperClass:
super_class_var = "superclass class variable: self.super_class_var"
__priv_super_class_var = "private superclass class variable: no access"
def __init__(self):
self.super_instance_var = (
"superclass instance variable: self.super_instance_var "
)
self.__psiv = "private superclass instance variable: no access"
def super_class_method(self):
return "superclass method: self.super_class_method()"
def superclass_priv_method(self):
return "superclass private method: no access"
class Class_(SuperClass):
class_var = "class variable: self.class_var or Class_.class_var (for assignment)"
__priv_class_var = (
"class private variable: self.__priv_class_var or Class_.__priv_class_var "
)
def __init__(self):
SuperClass.__init__(self)
self.__priv_instance_var = "private instance variable: self.__priv_instance_var"
def method_2(self):
return "method: self.method_2()"
def __priv_method(self):
return "private method: self.__priv_method()"
def method_1(self, param="parameter: param"):
# Local namespace
local_var = "local variable: local_var"
self.instance_var = "instance variable: self.instance_var"
print("Local")
print("Access local, global and built-in namespaces directly")
print("local namespace:", list(locals().keys()))
print(param) # <-- Parameter
print(local_var) # <-- Local variable
print()
# Global namespace
print("global namespace:", list(globals().keys()))
print(mod_var) # <-- Module variable
print(mod_func()) # <-- Module function
print()
# Instance namespace
print("Access instance, class, and superclass namespaces through 'self'")
print("Instance namespace:", self.__dict__)
print(self.instance_var) # <-- Instance variable
print(self.__priv_instance_var) # <-- Private instance variable
print(self.super_instance_var) # <-- Superclass instance variable
# Class namespace
print("\nClass_ namespace:", Class_.__dict__)
print(self.class_var) # <-- Class variable
print(self.method_2()) # <-- Method
print(self.__priv_class_var) # <-- Private class variable
print(self.__priv_method()) # <-- Private method
# Superclass namespace
print("\nSuperclass namespace:", SuperClass.__dict__)
print(self.super_class_method()) # <-- Superclass method
print(self.super_class_var) # <-- Superclass class variable through instanceThis output is considerable, so we’ll look at it in pieces.
In the first part, class Class_’s method method_1’s local namespace contains the parameters self (which is the instance variable) and param along with the local variable local_var (all of which can be accessed directly):
import cs
c = cs.Class_()
c.method_1()
#> Access local, global and built-in namespaces directly
#> local namespace: ['self', 'param', 'local_var']
#> parameter: param
#> local variable: local_varNext, method method_1’s global namespace contains the module variable mod_var and the module function mod_func (which, as described in a previous section, you can use to provide a class method functionality). There are also the classes defined in the module (the class Class_ and the superclass SuperClass). All these classes can be directly accessed:
global namespace: ['__name__', '__doc__', '__package__', '__loader__',
'__spec__', '__builtin__', '__builtins__', 'mod_var', 'mod_func',
'SuperClass', ]
module variable: mod_var
module level function: mod_func()Instance c’s namespace contains instance variable instance_var and the superclass’s instance variable super_instance_var (which, as described in a previous section, is no different from the regular instance variable). It also has the mangled name of private instance variable __priv_instance_var (which you can access through self) and the mangled name of the superclass’s private instance variable __psiv (which you can’t access):
Access instance, class, and superclass namespaces through 'self'
Instance namespace: {'super_instance_var': 'superclass instance variable:
self.super_instance_var ', '_SuperClass__psiv': 'private superclass
instance variable: no access', '_Class___priv_instance_var': 'private
instance variable: self.__priv_instance_var', 'instance_var': 'instance variable: self.instance_var'}
instance variable: self.instance_var
private instance variable: self.__priv_instance_var
superclass instance variable: self.super_instance_var Class Class_’s namespace contains the class variable class_var and the mangled name of the private class variable __priv_class_var. Both can be accessed through self, but to assign to them, you need to use class Class_. Class Class_ also has the class’s two methods method_1 and method_2, along with the mangled name of the private method __priv_method (which can be accessed through self):
Class_ namespace: {'__module__': '__main__', 'class_var': 'class variable:
self.class_var or Class_.class_var (for assignment)',
'_Class___priv_class_var': 'class private variable: self.__priv_class_var
or Class_.__priv_class_var ', '__init__': <function Class_.__init__ at
0x7b4b3e3dbeb0>, 'method_2': <function Class_.method_2 at 0x7b4b3e3db640>,
'_Class___priv_method': <function Class_.__priv_method at 0x7b4b3e3da560>,
'method_1': <function Class_.method_1 at 0x7b4b3e3db520>, '__doc__': None}
class variable: self.class_var or Class_.class_var (for assignment)
method: self.method_2()
class private variable: self.__priv_class_var or Class_.__priv_class_var
private method: self.__priv_method()Finally, superclass SuperClass’s namespace contains superclass class variable super_ class_var (which can be accessed through self, but to assign to it, you need to use the superclass SuperClass) and superclass method super_class_method. It also contains the mangled names of private superclass method superclass_priv_method and private superclass class variable __priv_super_class_var, neither of which can be accessed through self:
Superclass namespace: {'__module__': '__main__', 'super_class_var':
'superclass class variable: self.super_class_var',
'_SuperClass__priv_super_class_var': 'private superclass class variable: no
access', '__init__': <function SuperClass.__init__ at 0x7b4b3e3d9360>,
'super_class_method': <function SuperClass.super_class_method at
0x7b4b3e3d9480>, 'superclass_priv_method': <function
SuperClass.superclass_priv_method at 0x7b4b3e3d9120>, '__dict__':
<attribute '__dict__' of 'SuperClass' objects>, '__weakref__': <attribute
'__weakref__' of 'SuperClass' objects>, '__doc__': None}
superclass method: self.super_class_method()
superclass class variable: self.super_class_varThis example is a rather full one to decipher at first. You can use it as a reference or a base for your own exploration. As with most other concepts in Python, you can build a solid understanding of what’s going on by experimenting with a few simplified examples.
15.12 Destructors and memory management
You’ve already seen class initializers (the __init__ methods). A destructor can be defined for a class as well. But unlike in C++, creating and calling a destructor isn’t necessary to ensure that the memory used by your instance is freed. Python provides automatic memory management through a reference-counting mechanism. That is, it keeps track of the number of references to your instance; when this number reaches zero, the memory used by your instance is reclaimed, and any Python objects referenced by your instance have their reference counts decremented by one. You almost never need to define a destructor.
You may occasionally encounter a situation in which you need to deallocate an external resource explicitly when an object is removed. In such a situation, the best practice is to use a context manager, as discussed in chapter 14. As mentioned there, you can use the contextlib module from the standard library to create a custom context manager for your situation.
15.13 Multiple inheritance
Compiled languages place severe restrictions on the use of multiple inheritance—the ability of objects to inherit data and behavior from more than one parent class. The rules for using multiple inheritance in C++, for example, are so complex that many people avoid using it. In Java, multiple inheritance is disallowed, although Java does have an interface mechanism.
Python places no such restrictions on multiple inheritance. A class can inherit from any number of parent classes in the same way that it can inherit from a single parent class. In the simplest case, none of the involved classes, including those inherited indirectly through a parent class, contains instance variables or methods of the same name. In such a case, the inheriting class behaves like a synthesis of its own definitions and all of its ancestors’ definitions. Suppose that class A inherits from classes B, C, and D; class B inherits from classes E and F; and class D inherits from class G (see figure 15.3). Also suppose that none of these classes shares method names. In this case, an instance of class A can be used as though it were an instance of any of the classes B–G, as well as A; an instance of class B can be used as though it were an instance of class E or F as well as class B; and an instance of class D can be used as though it were an instance of class G as well as class D. In terms of code, the class definitions look like this:
class E:
. . .
class F:
. . .
class G:
. . .
class D(G):
. . .
class C:
. . .
class B(E, F):
. . .
class A(B, C, D):
. . .The situation is more complex when some of the classes share method names, because Python must decide which of the identical names is the correct one. Suppose that you want to resolve a method invocation ‘a.f()’ on an instance a of class A, where f isn’t defined in A but is defined in all of F, C, and G. Which of the various methods will be invoked?
The answer lies in the order in which Python searches base classes when looking for a method not defined in the original class on which the method was invoked. In the simplest cases, Python looks through the base classes of the original class in left-to-right order, but it always looks through all of the ancestor classes of a base class before looking in the next base class. In attempting to execute a.f(), the search goes something like this:
- Python first looks in the class of the invoking object, class A.
- Because A doesn’t define a method f, Python starts looking in the base classes of A. The first base class of A is B, so Python starts looking in B.
- Because B doesn’t define a method f, Python continues its search of B by looking in the base classes of B. It starts by looking in the first base class of B, class E.
- E doesn’t define a method f and also has no base classes, so there’s no more searching to be done in E. Python goes back to class B and looks in the next base class of B, class F.
Class F does contain a method f, and because it was the first method found with the given name, it’s the method used. The methods called f in classes C and G are ignored.
Using internal logic like this isn’t likely to lead to the most readable or maintainable of programs, of course. And with more complex hierarchies, other factors come into play to make sure that no class is searched twice and to support cooperative calls to super.
But this hierarchy is probably more complex than you’d expect to see in practice. If you stick to the more standard uses of multiple inheritance, as in the creation of mixin or addin classes, you can easily keep things readable and avoid name clashes.
Some people have a strong conviction that multiple inheritance is a bad thing. It can certainly be misused, and nothing in Python forces you to use it. One of the biggest dangers seems to be creating inheritance hierarchies that are too deep, and multiple inheritance can sometimes be used to help keep this problem from happening. That topic is beyond the scope of this book. The example I use here only illustrates how multiple inheritance works in Python and doesn’t attempt to explain the use cases for it (such as in mixin or addin classes).
15.14 HTML classes
In this lab, you create classes to represent an HTML document. To keep things simple, assume that each element can contain only text and one subelement. So the <html> element contains only a <body> element, and the <body> element contains (optional) text and a <p> element that contains only text.
The key feature to implement is the __str__() method, which in turn calls its subelement’s __str__() method, so that the entire document is returned when the str() function is called on an <html> element. You can assume that any text comes before the subelement.
Here’s example output from using the classes:
para = p(text="this is some body text")
doc_body = body(text="This is the body", subelement=para)
doc = html(subelement=doc_body)
print(doc)
#> <html>
#> <body>
#> This is the body
#> <p>
#> this is some body text
#> </p>
#> </body>
#> </html>15.14.1 Solving the problem with AI-generated code 15.14.1
This problem is well suited to an AI solution as phrased, in that it specifies how the problem should be solved and gives some sample code and output. This shows in the results—the AI did a better job on this problem than any of the others so far.
15.14.2 Solutions and discussion 15.14.2
The point of this problem is to use the power of inheritance to avoid repetitive code and to use the ability of objects to model the behavior needed for the problem. That implies much more work on the base class and ideally very little on the subclasses.
The human solution
My solution puts most of the processing into the base class element and then creates subclasses with no new code, which rely totally on the base class for functionality:
class element:
def __init__(self, text=None, subelement=None):
self.subelement = subelement
self.text = text
def __str__(self):
value = f"<{self.__class__.__name__}>\n" # <-- Gets the instance's class and then the class name
if self.text:
value += f"{self.text}\n"
if self.subelement:
value += str(self.subelement)
value += f"</{self.__class__.__name__}>\n"
return value
class html(element):
pass # <-- pass is the minimum needed for an "empty" class.
class body(element):
pass
class p(element):
pass
# test
para = p(text="this is some body text")
doc_body = body(text="This is the body", subelement=para)
doc = html(subelement=doc_body)
print(doc)As mentioned earlier, this solution puts all of the code into the base class element, which has the advantage of making future changes quite simple. It also uses the class names as the text of the corresponding HTML tags, which means that adding classes to handle more HTML elements would be trivial. Since I have the habit of using lowercase for HTML tags, the class names are also lowercase, which is a minor violation of standard Python style, which calls for class names to be capitalized. In this case I would invoke the Zen of Python and say, “practicality beats purity,” but I’m sure others would disagree.
The AI solutions
For the Copilot solution, the prompt was very similar to the previous problem statement:
Create classes to represent an HTML document, and assume that each element can contain only text and one subelement. So the <html> element contains only a <body> element, and the <body> element contains (optional) text and a <p> element that contains only text.
The key feature to implement is the str() method, which in turn calls its subelement’s str() method so that the entire document is returned when the str() function is called on an element. You can assume that any text comes before the subelement.
Following is example output from using the classes:
para = p(text="this is some body text")
doc_body = body(text="This is the body", subelement=para)
doc = html(subelement=doc_body)
print(doc)The plan that Copilot created was
- 1 Create a base class Element with a __str__ method that returns the text and the string representation of the subelement.
- 2 Create classes Html, Body, and P that inherit from Element.
- 3 Each class will have a tag class attribute that represents the HTML tag.
- 4 The __str__ method in the base class will use the tag to create the HTML string.
The solution that Copilot suggested was similar to my solution with a couple of stylistic differences:
class Element:
tag = ""
def __init__(self, text="", subelement=None):
self.text = text
self.subelement = subelement
def __str__(self):
result = f"<{self.tag}>\n"
if self.text:
result += self.text + "\n"
if self.subelement:
result += str(self.subelement)
result += f"</{self.tag}>\n"
return result
class Html(Element):
tag = "html"
class Body(Element):
tag = "body"
class P(Element):
tag = "p"
# Usage:
para = P(text="this is some body text")
doc_body = Body(text="This is the body", subelement=para)
doc = Html(subelement=doc_body)
print(doc)This code is fine, and I wouldn’t make any changes. It is similar to the human solution in that it puts the functionality into the base class. It differs from the human solution in only two aspects. First, it follows the Python convention of capitalizing class names. Since the example code it was given put the HTML in lowercase, the solution is then to use a class attribute tag to hold the lowercase tag name. That approach is fine—there isn’t a difference in the size or efficiency of the code, nor, I would argue, is there much difference in readability. So, well done, Copilot!
The Colaboratory solution was disappointing. Since the prompt window for code generation in Colaboratory is limited to 400 characters, and the prompt used for Copilot was nearly twice that size, the problem statement was placed in the cell above and Colaboratory was given this prompt:
Generate the code described in the cell above.
The result of that prompt was good enough to show that the model did process the prompt, but the solution has a lot of duplicated code that doesn’t take advantage of inheritance:
# prompt: Generate the code described in the cell above.
class html:
def __init__(self, subelement):
self.subelement = subelement
def __str__(self):
return f'<html>\n{str(self.subelement)}\n</html>'
class body:
def __init__(self, text, subelement=None):
self.text = text
self.subelement = subelement
def __str__(self):
sub = ''
if self.subelement:
sub = f'\n{str(self.subelement)}'
return f'<body>\n{self.text}{sub}\n</body>'
class p:
def __init__(self, text):
self.text = text
def __str__(self):
return f'<p>\n{self.text}\n</p>'
para = p(text="this is some body text")
doc_body = body(text="This is the body", subelement=para)
doc = html(subelement=doc_body)
print(doc)In fact, this was the only one of four suggested options that used f-strings—the other options used string concatenation with the + operator but took the same general approach. More to the point, this solution creates a new class for every tag, and there is no common base class that the elements inherit from. This means that the processing is duplicated, with only minor differences between the three elements. This code strikes me as something I would expect a junior developer to write, and it would not make it through code review as written.
Summary
- Defining a class in effect creates a new data type.
- __init__ is used to initialize data when a new instance of a class is created, but it isn’t a constructor.
- The self parameter refers to the current instance of the class and is passed as the first parameter to methods of a class.
- Static methods can be called without creating an instance of the class, so they don’t receive a self parameter.
- Class methods are passed a cls parameter, which is a reference to the class, instead of self.
- All Python methods are virtual. That is, if a method isn’t overridden in the subclass or private to the superclass, it’s accessible by all subclasses.
- Class variables are inherited from superclasses unless they begin with two underscores (__), in which case they’re private and can’t easily be seen by subclasses. Methods can be made private in the same way.
- Properties let you have attributes with defined getter and setter methods, but they still behave like plain instance attributes.
- Python allows multiple inheritance, which is often used with mixin classes.
16. Regular expressions
This chapter covers
- Understanding regular expressions
- Creating regular expressions with special characters
- Using raw strings in regular expressions
- Extracting matched text from strings
- Substituting text with regular expressions
Some might wonder why I’m discussing regular expressions in this book at all. Regular expressions are implemented by a single Python module and are advanced enough that they don’t even come as part of the standard library in languages like C or Java. But if you’re using Python, you’re probably doing text parsing; if you’re doing that, regular expressions are too useful to be ignored. If you’ve used Perl, Tcl, or Linux/UNIX, you may be familiar with regular expressions; if not, this chapter goes into them in some detail.
16.1 What is a regular expression?
A regular expression (regex) is a way of recognizing and often extracting data from certain patterns of text. A regex that recognizes a piece of text or a string is said to match that text or string. A regex is defined by a string in which certain characters (the so-called metacharacters) can have a special meaning, which enables a single regex to match many different specific strings.
It’s easier to understand this through example than through explanation. The following is a program with a regular expression that counts how many lines in a text file contain the word hello. A line that contains hello more than once is counted only once:
import re
regexp = re.compile("hello")
count = 0
file = open("textfile", 'r')
for line in file.readlines():
if regexp.search(line):
count = count + 1
file.close()
print(count)The program starts by importing the Python regular expression module, called re. Then it takes the text string “hello” as a textual regular expression and compiles it into a compiled regular expression, using the re.compile function. This compilation isn’t strictly necessary, but compiled regular expressions can significantly increase a program’s speed, so they’re almost always used in programs that process large amounts of text.
What can the regex compiled from “hello” be used for? You can use it to recognize other instances of the word “hello” within another string; in other words, you can use it to determine whether another string contains “hello” as a substring. This task is accomplished by the search method, which returns None if the regular expression isn’t found in the string argument; Python interprets None as false in a Boolean context. If the regular expression is found in the string, Python returns a special object that you can use to determine various things about the match (such as where in the string it occurred). I discuss this topic later.
16.2 Regular expressions with special characters
The previous example has a small flaw: it counts how many lines contain “hello” but ignores lines that contain “Hello” because it doesn’t take capitalization into account.
One way to solve this problem would be to use two regular expressions—one for “hello” and one for “Hello”—and test each against every line. A better way is to use the more advanced features of regular expressions. For the second line in the program, substitute
This regular expression uses the vertical-bar special character |. A special character is a character in a regex that isn’t interpreted as itself; it has some special meaning. | means or, so the regular expression matches “hello” or “Hello”.
Another way of solving this problem is to use
regexp = re.compile(“(h|H)ello”)
In addition to using |, this regular expression uses the parentheses special characters to group things, which in this case means that the | chooses between a small or capital H. The resulting regex matches either an h or an H, followed by ello.
Another way to perform the match is
regexp = re.compile("[hH]ello")The special characters [ and ] take a string of characters between them and match any single character in that string. There’s a special shorthand to denote ranges of characters in [ and ]; [a-z] matches a single character between a and z, [0-9A-Z] matches any digit or any uppercase character, and so forth. Sometimes you may want to include a real hyphen in the [], in which case you should put it as the first character to avoid defining a range; [-012] matches a hyphen, a 0, a 1, or a 2, and nothing else.
Quite a few special characters are available in Python regular expressions, and describing all of the subtleties of using them in regular expressions is beyond the scope of this book. A complete list of the special characters available in Python regular expressions, as well as descriptions of what they mean, is in the online documentation of the regular expression re module in the standard library. For the remainder of this chapter, I describe the special characters I use as they appear.
What regular expression would you use to match strings that represent the numbers –5 through 5?
What regular expression would you use to match a hexadecimal digit? Assume that allowed hexadecimal digits are 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, A, a, B, b, C, c, D, d, E, e, F, and f.
16.3 Regular expressions and raw strings
The functions that compile regular expressions, or search for matches to regular expressions, understand that certain character sequences in strings have special meanings in the context of regular expressions. regex functions understand that represents a newline character, for example. But if you use normal Python strings as regular expressions, the regex functions typically never see such special sequences, because many of these sequences also possess a special meaning in normal strings. , for example, also means newline in the context of a normal Python string, and Python automatically replaces the string sequence with a newline character before the regex function ever sees that sequence. The regex function, as a result, compiles strings with embedded newline characters—not with embedded sequences.
In the case of , this situation makes no difference because regex functions interpret a newline character as exactly that and do the expected thing: attempt to match the character with another newline character in the text being searched.
Now look at another special sequence, \, which represents a single backslash to regular expressions. Assume that you want to search text for an occurrence of the string “”. Because you know that you have to represent a backslash as a double backslash, you might try
regexp = re.compile("\\ten")This example compiles without complaining, but it’s wrong. The problem is that \ also means a single backslash in Python strings. Before re.compile is invoked, Python interprets the string you typed as meaning , which is what is passed to re.compile. In the context of regular expressions, eans tab, so your compiled regular expression searches for a tab character followed by the two characters en.
To fix this problem while using regular Python strings, you need four backslashes. Python interprets the first two backslashes as a special sequence representing a single backslash, and likewise for the second pair of backslashes, resulting in two actual backslashes in the Python string. Then that string is passed in to re.compile, which interprets the two actual backslashes as a regex special sequence representing a single backslash. Your code looks like this:
regexp = re.compile("\\\\ten")That seems confusing, and it’s why Python has a way of defining strings that doesn’t apply the normal Python rules to special characters. Strings defined this way are called raw strings.
16.3.1 Raw strings to the rescue
A raw string looks similar to a normal string except that it has a leading r character immediately preceding the initial quotation mark of the string. The following are some raw strings:
r"Hello"
r"""\tTo be\n\tor not to be"""
r'Goodbye'
r'''12345'''As you can see, you can use raw strings with either the single or double quotation marks and with the regular or triple-quoting convention. You can also use a leading R instead of r. No matter how you do it, raw-string notation can be taken as an instruction to Python: “Don’t process special sequences in this string.” In the previous examples, all the raw strings are equivalent to their normal string counterparts except the second example, in which the nd sequences aren’t interpreted as tabs or newlines but are left as two-string character sequences beginning with a backslash.
Raw strings aren’t different types of strings. They represent a different way of defining strings. It’s easy to see what’s happening by running a few examples interactively:
r"Hello" == "Hello"
True
r"\the" == "\\the"
True
r"\the" == "\the"
False
print(r"\the")
\the
print("\the")
heUsing raw strings with regular expressions means that you don’t need to worry about any funny interactions between string special sequences and regex special sequences. You use the regex special sequences. Then the previous regex example becomes
regexp = re.compile(r"\\ten")which works as expected. The compiled regex looks for a single backslash followed by the letters ten.
You should get into the habit of using raw strings whenever defining regular expressions, and you’ll do so for the remainder of this chapter.
16.4 Extracting matched text from strings
One common use of regular expressions is to perform simple pattern-based parsing on text. This task is something you should know how to do, and it’s also a good way to learn more regex special characters.
Assume that you have a list of people and phone numbers in a text file. Each line of the file looks like this:
surname, firstname middlename: phonenumber
You have a surname followed by a comma and space, followed by a first name, followed by a space, followed by a middle name, followed by a colon and a space, followed by a phone number.
But to make things complicated, a middle name may not exist, and a phone number may have different formats depending on the country and the users’ preferences. For our purposes, let’s assume that the only phone numbers will be in US/Canadian format with a three-digit area code, a three-digit exchange, and a four-digit number, separated by dashes, like 800-123-4567. Even so, a phone number might not have an area code. (It might be 800-123-4567 or 123-4567.) You could write code to explicitly parse data out from such a line, but that job would be tedious and error prone. Regular expressions provide a simpler answer.
Start by coming up with a regex that matches lines of the given form. The next few paragraphs throw quite a few special characters at you. Don’t worry if you don’t get them all on the first read; as long as you understand the gist of things, that’s all right.
For simplicity’s sake, assume that first names, surnames, and middle names consist of letters and possibly hyphens. You can use the [] special characters discussed in the previous section to define a pattern that defines only name characters:
[-a-zA-Z]This pattern matches a single hyphen, a single lowercase letter, or a single uppercase letter.
To match a full name (such as McDonald), you need to repeat this pattern. The + metacharacter repeats whatever comes before it one or more times as necessary to match the string being processed. So the pattern
[-a-zA-Z]+matches a single name, such as Kenneth or McDonald or Perkin-Elmer. It also matches some strings that aren’t names, such as — or -a-b-c-, but that’s all right for the purposes of this example.
Now, what about the phone number? The special sequence atches any digit, and a hyphen outside [] is a normal hyphen. A good pattern to match the phone number is
\d\d\d-\d\d\d-\d\d\d\dThat’s three digits followed by a hyphen, followed by three digits, followed by a hyphen, followed by four digits. This pattern matches only phone numbers with an area code, and your list may contain numbers that don’t have one. The best solution is to enclose the area-code part of the pattern in (); group it; and follow that group with a ? special character, which says that the thing coming immediately before the ? is optional:
(\d\d\d-)?\d\d\d-\d\d\d\dThis pattern matches a phone number that may or may not contain an area code. You can use the same sort of trick to account for the fact that some of the people in your list have middle names (or initials) included and others don’t. (Make the middle name optional by using grouping and the ? special character.)
You can also use {} to indicate the number of times that a pattern should repeat, so for the preceding phone number examples, you could use:
(-)?-
This pattern also means an optional group of three digits plus a hyphen, three digits followed by a hyphen, and then four digits.
Commas, colons, and spaces don’t have any special meanings in regular expressions; they mean themselves.
Putting everything together, you come up with a pattern that looks like the following:
[-a-zA-Z]+, [-a-zA-Z]+( [-a-zA-Z]+)?: (-)?-
A real pattern probably would be a bit more complex, because you wouldn’t assume that there’s exactly one space after the comma, exactly one space after the first and middle names, and exactly one space after the colon. But that’s easy to add later.
The problem is that, whereas the preceding pattern lets you check to see whether a line has the anticipated format, you can’t extract any data yet. All you can do is write a program like the following:
import re
regexp = re.compile(r"[-a-zA-Z]+,"
r" [-a-zA-Z]+"
r"( [-a-zA-Z]+)?"
r": (\d{3}-)?\d{3}-\d{4}"
)
file = open("textfile", 'r')
for line in file.readlines():
if regexp.search(line):
print("Yeah, I found a line with a name and number. So what?")
break
file.close()
Last name and comma
First name
Optional middle name
Colon and phone numberNotice that you’ve split your regex pattern, using the fact that Python implicitly concatenates any set of strings separated by whitespace. As your pattern grows, this technique can be a great aid in keeping the pattern maintainable and understandable. It also solves the problem with the line length possibly increasing beyond the right edge of the screen.
Fortunately, you can use regular expressions to extract data from patterns, as well as to see whether the patterns exist. The first step is to group each subpattern corresponding to a piece of data you want to extract by using the () special characters. Then give each subpattern a unique name with the special sequence ?P
(?P<last>[-a-zA-Z]+), (?P<first>[-a-zA-Z]+)( (?P<middle>([-a-zA-Z]+)))?:
(?P<phone>(\d{3}-)?\d{3}-\d{4}(Please note that you should enter these lines as a single line, with no line breaks. Due to space constraints, the code can’t be represented here in that manner.)
There’s an obvious point of confusion here: The question marks in ?P<…> and the question mark special characters indicating that the middle name and area code are optional have nothing to do with one another. It’s an unfortunate semicoincidence that they happen to be the same character.
Now that you’ve named the elements of the pattern, you can extract the matches for those elements by using the group method. You can do so because when the search function returns a successful match, it doesn’t return just a truth value; it also returns a data structure that records what was matched. You can write a simple program to extract names and phone numbers from your list and print them out again, as follows:
import re
regexp = re.compile(r"(?P<last>[-a-zA-Z]+),"
r" (?P<first>[-a-zA-Z]+)"
r"( (?P<middle>([-a-zA-Z]+)))?"
r": (?P<phone>((\d{3}-)?\d{3}-\d{4}))"
)
file = open("textfile", 'r')
for line in file.readlines():
result = regexp.search(line)
if result == None:
print("Oops, I don't think this is a record")
else:
last_name = result.group('last')
first_name = result.group('first')
middle_name = result.group('middle')
if middle_name == None:
middle_name = ""
phone_number = result.group('phone')
print(f"Name: {first_name} {middle_name} {last_name} Number:
{phone_number}")file.close()
Last name and comma
First name
Optional middle name
Colon and phone
number
No match foundThere are some points of interest here:
- You can find out whether a match succeeded by checking the value returned by search. If the value is None, the match failed; otherwise, the match succeeded, and you can extract information from the object returned by search.
- group is used to extract whatever data matched your named subpatterns. You pass in the name of the subpattern you’re interested in.
- Because the middle subpattern is optional, you can’t count on it to have a value, even if the match as a whole is successful. If the match succeeds but the match for the middle name doesn’t, using group to access the data associated with the middle subpattern returns the value None.
- Part of the phone number is optional, but part isn’t. If the match succeeds, the phone subpattern must have some associated text, so you don’t have to worry about it having a value of None.
Making international calls usually requires a + and the country code. Assuming that the country code is two digits, how would you modify the preceding code to extract the + and the country code as part of the number? (Again, not all numbers have a country code.) How would you make the code handle country codes of one to three digits?
16.5 Substituting text with regular expressions
In addition to extracting strings from text, you can use Python’s regex module to find strings in text and substitute other strings in place of those that were found. You accomplish this task by using the regular substitution method sub. The following example replaces instances of “the the” (presumably, a typo) with single instances of “the”:
import re
string = "If the the problem is textual, use the the re module"
pattern = r"the the"
regexp = re.compile(pattern)
regexp.sub("the", string)
'If the problem is textual, use the re module'The sub method uses the invoking regex (regexp, in this case) to scan its second argument (string, in the example) and produces a new string by replacing all matching substrings with the value of the first argument (“the”, in this example).
16.5.1 Using a function with sub
But what if you want to replace the matched substrings with new ones that reflect the value of those that matched? This is where the elegance of Python comes into play. The first argument to sub—the replacement substring, “the” in the example—doesn’t have to be a string at all. Instead, it can be a function. If it’s a function, Python calls it with the current match object; then it lets that function compute and return a replacement string.
To see this function in action, build an example that takes a string containing integer values (no decimal point or decimal part) and returns a string with the same numerical values but as floating-point numbers (with a trailing decimal point and zero):
import re
int_string = "1 2 3 4 5"
def int_match_to_float(match_obj): return(match_obj.group('num') + ".0")
pattern = r"(?P<num>[0-9]+)"
regexp = re.compile(pattern)
regexp.sub(int_match_to_float, int_string)‘1.0 2.0 3.0 4.0 5.0’
In this case, the pattern looks for a number consisting of one or more digits (the [0-9]+ part). But it’s also given a name (the ?P
In the checkpoint in section 16.4, you extended a phone number regular expression to also recognize a country code. How would you use a function to make any numbers that didn’t have a country code now have +1 (the country code for the United States and Canada)?
16.6 Phone number normalizer
In the United States and Canada, phone numbers consist of 10 digits, usually separated into a three-digit area code, a three-digit exchange code, and a four-digit station code. As mentioned in section 16.4, they may or may not be preceded by +1, the country code. In practice, however, you have many ways to format a phone number, such as (NNN) NNN-NNNN, NNN-NNN-NNNN, NNN NNN-NNNN, NNN.NNN.NNNN, and NNN NNN NNNN, to name a few. Also, the country code may not be present, may not have a +, and usually (not always) is separated from the number by a space or dash. Whew!
In this lab, your task is to create a phone number normalizer that takes any of the formats and returns a normalized phone number 1-NNN-NNN-NNNN.
The following are all possible phone numbers:
| +1 223-456-7890 | 1-223-456-7890 | +1 223 456-7890 |
|---|---|---|
| (223) 456-7890 | 1 223 456 7890 | 223.456.7890 |
Bonus: The first digit of the area code and the exchange code can only be 2 to 9, and the second digit of an area code can’t be 9. Use this information to validate the input and return a ValueError exception of invalid phone number if the number is invalid.
16.6.1 Solving the problem with AI-generated code
Programmers like to joke that if you have a problem and decide to use a regular expression to solve it, you now have two problems. There’s some truth to that, since it can be tricky to get a regular expression to do all that you want and only what you want. You need to be very careful testing your code to make sure your tests cover all of your desired positive matches as well as the cases you expect not to match. Do not trust the AI to create a perfect solution or to generate the right test cases.
16.6.2 Solutions and discussion
There are a couple of approaches to this problem. You can try to match the most likely phone number patterns, which was my approach, or you can try to strip out everything but the numbers and then add the separators. If in fact you know that the input will be a phone number, the second approach is probably better.
The human solution
My solution uses a function to normalize the numbers as the main regular expression’s parameter and two additional regular expressions in that function to check for illegal numbers:
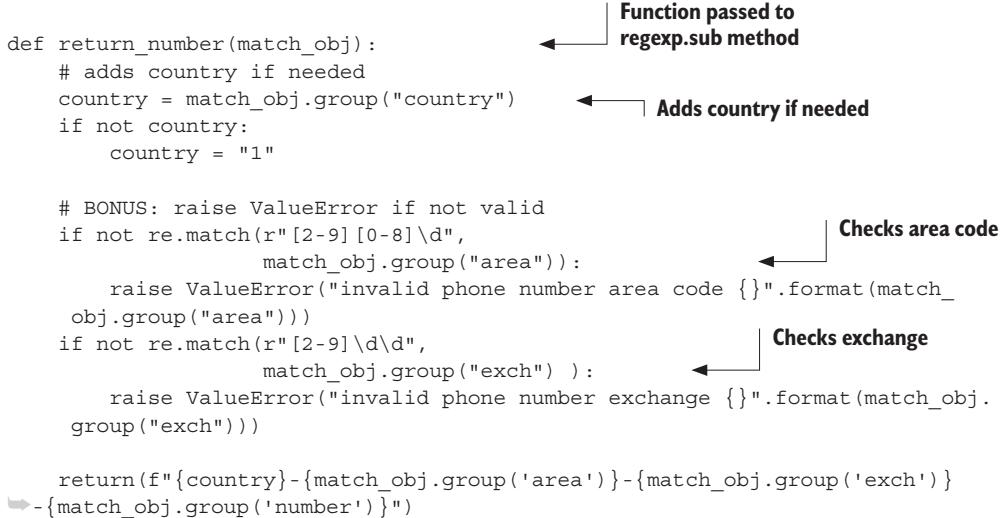
regexp = re.compile(r"\+?(?P<country>\d{1,3})?[- .]?\(?(?P<area>\d{3})\)
➥?[- .]?(?P<exch>(\d{3}))[- .](?P<number>\d{4})")
for number in test_numbers:
print(regexp.sub(return_number, number))
# Test
phone_numbers = ["+1 223-456-7890",
"1-223-456-7890",
"+1 223 456-7890",
"(223) 456-7890",
"1 223 456 7890",
"999.456.7890",
"1-989-111-2222",
"223.456.7890"]
regexp = re.compile(r"\+?(?P<country>\d{1,3})?[- .]?\(?(?P<area>\d{3})\)
➥?[- .]?(?P<exch>(\d{3}))[- .](?P<number>\d{4})")
for number in test_numbers:
try:
normalized_phone_number = regexp.sub(return_number, number)
print(f'{normalized_phone_number}')
except ValueError as e:
print(f'{number} is not a valid phone number: {e}')
1-223-456-7890
1-223-456-7890
1-223-456-7890
1-223-456-7890
1-223-456-7890
999.456.7890 is invalid: invalid phone number area code 999
1-989-111-2222 is invalid: invalid phone number exchange 111
1-223-456-7890
Calls main regexpWhile regular expressions themselves can be tricky, the code that uses them usually isn’t. In this case, the work is done by the function return_number, which is passed to the main regular expression sub method as the first parameter.
That function checks to see if there is a country code and adds +1 if there isn’t. It then uses two other regular expressions to check the area code and exchange to make sure they are allowed and raises a ValueError with the appropriate message if not. One obvious optimization that this code does not implement would be to precompile the area code and exchange regular expressions.
The main regular expression looks to match the most common separators but will not handle numbers that use different separators, nor different groupings of numbers. On reflection, it might have made more sense to assume that the separator patterns don’t matter and just extract the digits.
The AI solutions
Copilot came up with a reasonable solution by first stripping nonnumeric characters and then worrying about the checking and formatting. The prompt used was
import re
def normalize_phone_number(phone_number):
phone_number = re.sub(r'\D', '', phone_number)
if len(phone_number) not in [10, 11]:
raise ValueError("Invalid phone number length")
if not re.match(r'^[2-9][0-8][0-9][2-9]',
phone_number[-10:]):
raise ValueError("Invalid area code or exchange code")
if len(phone_number) == 10:
phone_number = '1' + phone_number
phone_number = re.sub(r'(\d{1})(\d{3})(\d{3})(\d{4})',
r'\1-\2-\3-\4', phone_number)
return phone_number
# Test the function.
phone_numbers = ["+1 223-456-7890",
"1-223-456-7890",
"+1 223 456-7890",
"(223) 456-7890",
"1 223 456 7890",
"999.456.7890",
"1-989-111-2222",
"223.456.7890"]
for number in test_numbers:
try:
normalized_phone_number = normalize_phone_number(number)
print(f'{normalized_phone_number}')
except ValueError as e:
print(f'{number} is not a valid phone number: {e}')
1-223-456-7890
1-223-456-7890
1-223-456-7890
1-223-456-7890
1-223-456-7890
999.456.7890 is invalid: Invalid area code or exchange code
1-989-111-2222 is invalid: Invalid area code or exchange code
1-223-456-7890
Removes all nondigit
(\D) characters
The length must be 10 or 11.
Checks area code
and exchange at once
Adds country code if needed
Adds dashes between
elementsThe first thing this code does is replace all nondigit characters () in the string, leaving only digits. If the length is not 10 or 11 digits, there must be an error, which is raised. The next regular expression looks at the last 10 digits and checks to make sure that the first four digits are correct, with 1 not allowed in the first or fourth position and 9 not allowed in the second position. It also checks the third position but allows all digits there. Then, if the string is only 10 digits long, it adds a 1 at the front. Finally, it uses a sub to group the digits appropriately and insert dashes.
In my opinion this solution is arguably more flexible and robust than my own solution. This solution also does not precompile the regular expressions, which would be a good idea in production. I would have only two other caveats. First, if the input could have letters and other characters in them along with the digits, this solution will accept them without complaint, as long as the number of digits is 10 or 11. That might not be a good thing. The other more minor caveat is that the error message returned for illegal digits in the area code or exchange is not very specific and should be a bit friendlier to debugging.
Colaboratory was given a similar prompt (in a separate notebook in a fresh session, to prevent it from “cheating” from the other solutions). Again, to work around the limitation on prompt lengths, the prompt was entered into a text cell and the then the AI generator was directed to that cell:
Using regular expressions, write code to normalize phone numbers in formats (NNN) NNN-NNNN, NNN-NNN-NNNN, NNN NNN-NNNN, NNN.NNN.NNNN, and NNN NNN NNNN (with or without a country code and a +) to 1-NNN-NNN-NNNN. Also raise a ValueError if the first digit of the area code and the exchange code is not 2-9, or the second digit of the area code is 9.
Write the code to normalize phone numbers as specified in the cell above.
Unfortunately, all four of the options offered by Colaboratory were unsatisfactory, with two being unable to run without errors. Another option incorrectly flagged numbers with a 1 country code as illegal but passed a number with a 999 area code, and removed spaces, dots, hyphens, and parentheses with an ugly chain of string replace calls:
phone_number.replace(' ', '').replace('.', '').replace('-',
'').replace('(', '').replace(')', '')The remaining solution took a similar approach Copilot’s, but with some problems:
# prompt: Write the code to normalize phone numbers as specified
# in the cell above.
import re
def normalize_phone_number(phone_number):
"""
Normalizes a phone number to the format 1-NNN-NNN-NNNN.
Args:
phone_number: The phone number to normalize.
Returns:
The normalized phone number.
Raises:
ValueError: If the phone number is not in a valid format.
""" # Remove all non-digit characters.
phone_number = re.sub(r'\D', '', phone_number)
# Check if the phone number is in a valid format.
if not re.match(r'^(1)?\d{10}$', phone_number):
raise ValueError('Invalid phone number format.')
# Check if the first digit of the area code and the exchange code
# is not 2-9, or the second digit of the area code is 9.
if not re.match(r'^1?[2-9]\d{2}[2-9]\d{6}$', phone_number):
raise ValueError('Invalid area code or exchange code.')
# Normalize the phone number to the format 1-NNN-NNN-NNNN.
return '-'.join([phone_number[0:1], phone_number[1:4], phone_number[4:7],
phone_number[7:]])
# Test the function.
phone_numbers = ["+1 223-456-7890",
"1-223-456-7890",
"+1 223 456-7890",
"(223) 456-7890",
"1 223 456 7890",
"999.456.7890",
"1-989-111-2222",
"223.456.7890"]
for number in test_numbers:
try:
normalized_phone_number = normalize_phone_number(number)
print(f'{normalized_phone_number}')
except ValueError as e:
print(f'{number} is not a valid phone number: {e}')
1-223-456-7890
1-223-456-7890
1-223-456-7890
2-234-567-890
1-223-456-7890
9-994-567-890
1-989-111-2222 is invalid: Invalid area code or exchange code.
2-234-567-890
Removes all nondigits (\D)
Checks for valid length,
prefix (if present)
Checks the first digits of
exchange and area code
Joins elements separated
by position in stringThe two main problems here are that this solution doesn’t actually add a 1 as a prefix if it’s missing, which fails the main part of the problem. The failure to add a 1 if needed then causes the elements to be off in those cases, returning the odd grouping of N-NNN-NNN-NNN. Yes, the number would still “work,” I suppose, but it’s not normalized as specified.
Second, this solution misses the bonus because it doesn’t check to make sure that the second digit of the area code is not a 9. It’s a little bit odd, since the comment placed immediately above that regular expression does explicitly mention that requirement.
In terms of performance, thanks to using a regular expression to insert the dashes, the Copilot version ends up taking about twice as long as my solution, which is the fastest. This isn’t surprising—for all their powers, regular expressions are not likely to be particularly fast, which is something to keep in mind if performance is vital.
Summary
- A regular expression (regex) is a way of recognizing and often extracting data from certain patterns of text.
- In Python, regular expressions are handled by the re module of the standard library.
- For a complete list and explanation of the regex special characters, refer to the Python documentation.
- Adding an ‘r’ before a string tells Python to handle it as a “raw” string and not process escape sequences.
- The most common regular expression methods are the search and sub methods.
- In addition to the search and sub methods, many other methods can be used to split strings, extract more information from match objects, look for the positions of substrings in the main argument string, and precisely control the iteration of a regex search over an argument string.
- Besides the pecial sequence, which can be used to indicate a digit character, many other special sequences are listed in the documentation.
- There are also regex flags, which you can use to control some of the more esoteric aspects of how extremely sophisticated matches are carried out.
- Regular expression methods can also be given a function to handle matches, in place of replacement expressions.
17. Data types as objects
This chapter covers
- Treating types as objects
- Using types
- Creating user-defined classes
- Understanding duck typing
- Using special method attributes
- Subclassing built-in types
By now you’ve learned the basic Python types as well as how to create your own data types using classes. For many languages, that would be pretty much it as far as data types are concerned. But Python is dynamically typed, meaning that types are determined at runtime, not compile time. This fact is one of the reasons Python is so easy to use. It also makes it possible, and sometimes necessary, to compute with the types of objects (not just the objects themselves).
17.1 Types are objects too
Fire up a Python session and try out the following:
type(5)<class 'int'>type(['hello', 'goodbye'])<class 'list'>This example is the first time we’ve seen the built-in type function in Python. It can be applied to any Python object and returns the type of that object. In this example, the function tells you that 5 is an int (integer) and that [‘hello’, ‘goodbye’] is a list things that you probably already knew.
Of greater interest is the fact that Python returns objects in response to the calls to type; <class ‘int’> and <class ‘list’> are the screen representations of the returned objects. What sort of object is returned by a call of type(5)? You have an easy way of finding out. Just use type on that result:
type_result = type(5)
type(type_result)<class 'type'>The object returned by type is an object whose type happens to be <class ‘type’>; you can call it a type object. A type object is what we commonly think of as a class, and while the two terms are used in somewhat different contexts, in fact “type” and “class” in Python refer to the same thing. Apart from the somewhat confusing notion that a type or class has the type <class ‘type’>, the important thing to understand is that classes (or types) in Python are objects like almost everything else.
17.2 Using types
Now that you know that data types can be represented as Python type objects, what can you do with them? You can compare them to see if they are equal, because any two Python objects can be compared:
type("Hello") == type("Goodbye")Truetype("Hello") == type(5)FalseThe types of “Hello” and “Goodbye” are the same (they’re both strings), but the types of “Hello” and 5 are different. Among other things, you could use this technique to provide type checking in your function and method definitions.
17.3 Types and user-defined classes
The most common reason to be interested in the types of objects, particularly instances of user-defined classes, is to find out whether a particular object is an instance of a class. After determining that an object is of a particular type, the code can treat it appropriately. An example makes things much clearer. To start, define a couple of empty classes to set up a simple inheritance hierarchy:
class A:
pass
class B(A):
passNow create an instance of class B:
b = B()As expected, applying the type function to b tells you that b is an instance of the class B that’s defined in your current __main__ namespace:
type(b)<class '__main__.B'>You can also obtain exactly the same information by accessing the instance’s special __class__ attribute:
b.__class__ <class '__main__.B'>You’ll be working with that class quite a bit to extract further information, so store it somewhere:
b_class = b.__class__Now, to emphasize that everything in Python is an object, prove that the class you obtained from b is the class you defined under the name B:
b_class == BTrueIn this example, you didn’t need to store the class of b—you already had it—but I want to make clear that a class is just another Python object and can be stored or passed around like any Python object.
Given the class of b, you can find the name of that class by using its __name___ attribute:
b_class.__name__'B'And you can find out what classes a class inherits from by accessing its __bases__ attribute, which contains a tuple of all of its base classes:
b_class.__bases__(<class '__main__.A'>,)Used together, __class__, __bases__, and __name__ allow a full analysis of the class inheritance structure associated with any instance.
But two built-in functions provide a more user-friendly way of obtaining most of the information you usually need: isinstance and issubclass. The isinstance function is what you should use to determine whether, for example, a class passed into a function or method is of the expected type:
class C:
pass
class D:
pass
class E(D):
pass
x = 12
c = C()
d = D()
e = E()isinstance(x, E)
False
isinstance(c, E) # <-- Checks instance against class E
False
isinstance(e, E)
True
isinstance(e, D) # <-- Checks against class D
True
isinstance(d, E) # <-- Checks d against E
False
y = 12
isinstance(y, type(5)) # <-- Uses type() plus example of class
TrueThe issubclass function is only for class types:
issubclass(C, D)
False
issubclass(E, D)
True
issubclass(D, D) # <-- Class is a subclass of itself.
True
issubclass(e.__class__, D)
TrueFor class instances, we first check x, c, and e against the class E. Then we see that e is an instance of class D because E inherits from D. But d isn’t an instance of class E. If we don’t have the class object handy, as with built-in types, we can use an instance of the class with the type function. A class is considered to be a subclass of itself.
Suppose that you want to make sure that object x is a list before you try appending to it. What code would you use? What would be the difference between using type() and isinstance()? Would this be the “look before you leap” or “easier to ask forgiveness than permission” of programming? What other options might you have besides checking the type explicitly?
17.4 Duck typing
Using type, isinstance, and issubclass makes it fairly easy to make code correctly determine an object’s or class’s inheritance hierarchy. Although this process is easy, Python also has a feature that makes using objects even easier: duck typing. Duck typing (as in “If it walks like a duck and quacks like a duck, it probably is a duck”) refers to Python’s way of determining whether an object is the required type for an operation, focusing on an object’s interface rather than its type. If an operation needs an iterator, for example, the object used doesn’t need to be a subclass of any particular iterator at all. All that matters is that the object used as an iterator is able to yield a series of objects in the expected way.
By contrast, in a language like Java, stricter rules of inheritance are enforced. In short, duck typing means that, in Python, you don’t need to worry about type-checking function or method arguments and the like. Instead, you should rely on readable and documented code combined with thorough testing to make sure that an object “quacks like a duck” as needed.
Duck typing can increase the flexibility of well-written code and, combined with the more advanced object-oriented features, gives you the ability to create classes and objects to cover almost any situation.
Particularly for larger codebases, the flexibility of duck typing can allow bugs to slip by undetected. It is becoming more common to avoid or restrict duck typing in favor of explicit type hints, which can be verified by a type checker.
17.5 What is a special method attribute?
A special method attribute is an attribute of a Python class with a special meaning to Python. It’s defined as a method but isn’t intended to be used directly by client code. Special methods aren’t usually directly invoked; instead, they’re called automatically by Python in response to a demand made on an object of that class.
Special method attributes are marked by double underscore characters at both ends of their names. For this reason, they are often referred to as “dunder” methods, short for “double underscore.” They are also sometimes called “magic” methods, since they power much of the “magic” of Python classes.
Perhaps the simplest example is the __str__ special method attribute. If it’s defined in a class, any time an instance of that class is used where Python requires a user-readable string representation of that instance, the __str__ method attribute is invoked, and the value it returns is used as the required string. To see this attribute in action, let’s define a class representing red, green, and blue (RGB) colors as a triplet of numbers, one each for red, green, and blue intensities. As well as defining the standard __init__ special method to initialize instances of the class, we’ll define a __str__ special method to return strings representing instances in a reasonably human-friendly format. The definition would look something like this.
Listing 17.1 File color_module.py
class Color:
def __init__(self, red, green, blue):
self._red = red
self._green = green
self._blue = blue
def __str__(self):
return f"Color: R={self._red:d},G={self._green:d},B={self._blue:d}"If you put this definition into a file called color_module.py, you can load it and use it in the normal manner:
from color_module import ColorOr, in Colaboratory, we could just execute the code in a cell and use it without importing:
c = Color(15, 35, 3)You can see the presence of the __str__ special method attribute if you use print to print out c:
print(c)Color: R=15, G=35, B=3Even though your __str__ special method attribute hasn’t been explicitly invoked by any of your code, it has nonetheless been used by Python, which knows that the __str__ attribute (if present) defines a method to convert objects into user-readable strings. This characteristic is the defining one of special method attributes; it allows you to define functionality that hooks into Python in special ways. Among other things, special method attributes can be used to define classes whose objects behave in a fashion that’s syntactically and semantically equivalent to lists or dictionaries. You could, for example, use this ability to define objects that are used in exactly the same manner as Python lists but that use balanced trees rather than arrays to store data. To a programmer, such objects would appear to be lists but with faster inserts, slower iterations, and certain other performance differences that presumably would be advantageous in the problem at hand.
The rest of this chapter covers longer examples using special method attributes. The chapter doesn’t discuss all of Python’s available special method attributes, but it does expose you to the concept in enough detail that you can easily use the other special attribute methods, all of which are defined in the standard library documentation for built-in types.
17.6 Making an object behave like a list
This example involves a large text file containing records of people; each record consists of a single line containing the person’s name, age, and place of residence, with a double semicolon (::) between the fields. A few lines from such a file might look like the following:
.
.
.
John Smith::37::Springfield, Massachusetts
Ellen Nelle::25::Springfield, Connecticut
Dale McGladdery::29::Springfield, Hawaii
.
.
.Suppose that you need to collect information about the distribution of ages of people in the file. There are many ways the lines in this file could be processed. Here’s one way:
fileobject = open(filename, 'r')
lines = fileobject.readlines()fileobject.close()
for line in lines:
. . . do whatever . . .That technique would work in theory, but it reads the entire file into memory at once. If the file were too large to be held in memory (and these files potentially are that large), the program wouldn’t work.
Another way to attack the problem is
fileobject = open(filename, 'r')
for line in fileobject:
. . . do whatever . . .
fileobject.close()This code would get around the problem of having too little memory by reading in only one line at a time. It would work fine, but suppose that you wanted to make opening the file even simpler and that you wanted to get only the first two fields (name and age) of the lines in the file. You’d need something that could, at least for the purposes of a for loop, treat a text file as a list of lines but without reading the entire text file in at once.
17.7 The __getitem__ special method attribute
A solution is to use the __getitem__ special method attribute, which you can define in any user-defined class, to enable instances of that class to respond to list access syntax and semantics. If AClass is a Python class that defines __getitem__, and obj is an instance of that class, things like x = obj[n] and for x in obj: are meaningful; obj may be used in much the same way as a list.
The resulting code for the LineReader class (explanations follow) is
By implementing a __getitem__() method, we enable instances of the class to be used as an iterable in the for loop, which reads a line of the file with each iteration. This will work as long as we also raise an IndexError to indicate that we have reached the end of the iterable’s items, which we do when reading from the file returns an empty string at the end of the file.
At first glance, this example may look worse than the previous solution because there’s more code, and it’s more difficult to understand. But most of that code is in a class, which can be put into its own module, such as the myutils module. Then the program becomes
import myutils
for name, age in myutils.LineReader("filename"):
. . . do whatever . . .The LineReader class handles all the details of opening the file, reading in lines one at a time, and closing the file. At the cost of somewhat more initial development time, it provides a tool that makes working with one-record-per-line large text files easier and less error prone. Note that Python already has several powerful ways to read files, but this example has the advantage that it’s fairly easy to understand. When you get the idea, you can apply the same principle in many situations.
17.7.1 How it works
LineReader is a class, and the __init__ method opens the named file for reading and stores the opened fileobject for later access. To understand the use of the __ getitem__ method, you need to know the following three points:
- Any object that defines __getitem__ as an instance method can return elements as though it were a list: all accesses of the form object[i] are transformed by Python into a method invocation of the form object.__getitem__(i), which is handled as a normal method invocation. It’s ultimately executed as __getitem__ (object, i), using the version of __getitem__ defined in the class. The first argument of each call of __getitem__ is the object from which data is being extracted, and the second argument is the index of that data.
- Because for loops access each piece of data in a list, one at a time, a loop of the form for arg in sequence: works by calling __getitem__ over and over again, with sequentially increasing indexes. The for loop first sets arg to sequence.__ getitem__(0), then to sequence.__getitem__(1), and so on.
- A for loop catches IndexError exceptions and handles them by exiting the loop. This process is how for loops are terminated when used with normal lists or sequences.
The LineReader class is intended for use only with and inside a for loop, and the for loop always generates calls with a uniformly increasing index: __getitem__(self, 0), __getitem__(self, 1), __getitem__(self, 2), and so on. The code at the beginning of section 17.7 takes advantage of this knowledge and returns lines one after the other, ignoring the index argument.
With this knowledge, understanding how a LineReader object emulates a sequence in a for loop is easy. Each iteration of the loop causes the special Python attribute method __getitem__ to be invoked on the object; as a result, the object reads in the next line from its stored fileobject and examines that line. If the line is nonempty, it’s returned. An empty line means that the end of the file has been reached; the object closes the fileobject and raises the IndexError exception. IndexError is caught by the enclosing for loop, which then terminates.
Remember that this example is here for illustrative purposes only. Usually, iterating over the lines of a file by using the for line in fileobject: type of loop is sufficient, but this example does show how easy it is in Python to create objects that behave like lists or other types.
The example use of __getitem__ is very limited and won’t work correctly in many situations. What are some cases in which the previous implementation will fail or work incorrectly?
17.7.2 Implementing full list functionality
In the previous example, an object of the LineReader class behaves like a list object only to the extent that it correctly responds to sequential accesses of the lines in the file it’s reading from. You may wonder how this functionality can be expanded to make LineReader (or other) objects behave more like a list.
First, the __getitem__ method should handle its index argument in some way. Because the whole point of the LineReader class is to avoid reading a large file into memory, it wouldn’t make sense to have the entire file in memory and return the appropriate line. Probably the smartest thing to do would be to check that each index in a __getitem__ call is 1 greater than the index from the previous __getitem__ call (or is 0, for the first call of __getitem__ on a LineReader instance) and to raise an error if this isn’t the case. This practice would ensure that LineReader instances are used only in for loops, as was intended.
More generally, Python provides several special method attributes relating to list behavior. __setitem__ provides a way of defining what should be done when an object is used in the syntactic context of a list assignment, obj[n] = val. Some other special method attributes provide less-obvious list functionality, such as the __add__ attribute, which enables objects to respond to the + operator and hence to perform their version of list concatenation. Several other special methods also need to be defined before a class fully emulates a list, but you can achieve complete list emulation by defining the appropriate Python special method attributes. The next section gives an example that goes further toward implementing a full list class.
17.8 Giving an object full list capability
__getitem__ is one of many Python special function attributes that may be defined in a class to permit instances of that class to display special behavior. To see how special method attributes can be carried further, effectively integrating new abilities into Python in a seamless manner, look at another, more comprehensive example.
When lists are used, it’s common for any particular list to contain elements of only one type, such as a list of strings or a list of numbers. Some languages, such as C++, have the ability to enforce this restriction. In large programs, the ability to declare a list as containing a certain type of element can help you track down errors. An attempt to add an element of the wrong type to a typed list results in an error message, potentially identifying a problem at an earlier stage of program development than would otherwise be the case.
Python doesn’t have typed lists built in, and most Python coders don’t miss them. But if you’re concerned about enforcing the homogeneity of a list, special method attributes make it easy to create a class that behaves like a typed list. The following is the beginning of such a class (which makes extensive use of the Python built-in type and isinstance functions to check the type of objects):
class TypedList:
def __init__(self, example_element, initial_list=[]):
self.type = type(example_element) # <-- An example of the type allowed
if not isinstance(initial_list, list):
raise TypeError("Second argument of TypedList must "
"be a list.")
for element in initial_list:
if not isinstance(element, self.type):
raise TypeError("Attempted to add an element of "
"incorrect type to a typed list.")
self.elements = initial_list[:]The example_element argument defines the type that this list can contain by providing an example of the type of element.
The TypedList class, as defined here, gives you the ability to make a call of the form
x = TypedList ('Hello', ["List", "of", "strings"])The first argument, ‘Hello’, isn’t incorporated into the resulting data structure at all. It’s used as an example of the type of element the list must contain (strings, in this case). The second argument is an optional list that can be used to give an initial list of values. The __init__ function for the TypedList class checks that any list elements, passed in when a TypedList instance is created, are of the same type as the example value given. If there are any type mismatches, an exception is raised.
This version of the TypedList class can’t be used as a list, because it doesn’t respond to the standard methods for setting or accessing list elements. To fix this problem, you need to define the __setitem__ and __getitem__ special method attributes. The __setitem__ method is called automatically by Python any time a statement of the form TypedListInstance[i] = value is executed, and the __getitem__ method is called any time the expression TypedListInstance[i] is evaluated to return the value in the ith slot of TypedListInstance. The following is the next version of the TypedList class. Because you’ll be type-checking a lot of new elements, this function is abstracted out into the new private method __check:
class TypedList:
def __init__(self, example_element, initial_list=[]):
self.type = type(example_element)
if not isinstance(initial_list, list):
raise TypeError("Second argument of TypedList must "
"be a list.")
for element in initial_list:
self.__check(element)
self.elements = initial_list[:]
def __check(self, element):
if type(element) != self.type:
raise TypeError("Attempted to add an element of "
"incorrect type to a typed list.")
def __setitem__(self, i, element):
self.__check(element)
self.elements[i] = element
def __getitem__(self, i):
return self.elements[i]Now instances of the TypedList class look more like lists. The following code is valid, for example:
x = TypedList("", 5 * [""])
x[2] = "Hello"
x[3] = "There"
print(x[2] + ' ' + x[3])Hello Therea, b, c, d, e = x
a, b, c, d('', '', 'Hello', 'There')The accesses of elements of x in the print statement are handled by __getitem__, which passes them down to the list instance stored in the TypedList object. The assignments to x[2] and x[3] are handled by __setitem__, which checks that the element being assigned into the list is of the appropriate type and then performs the assignment on the list contained in self.elements. The last line uses __getitem__ to unpack the first five items in x and then pack them into the variables a, b, c, d, and e, respectively. The calls to __getitem__ and __setitem__ are made automatically by Python.
Completion of the TypedList class, so that TypedList objects behave in all respects like list objects, requires more code. The special method attributes __setitem__ and __getitem__ should be defined so that TypedList instances can handle slice notation as well as single item access. __add__ should be defined so that list addition (concatenation) can be performed, and __mul__ should be defined so that list multiplication can be performed. __len__ should be defined so that calls of len(TypedListInstance) are evaluated correctly. __delitem__ should be defined so that the TypedList class can handle del statements correctly. Also, an append method should be defined so that elements can be appended to TypedList instances by means of the standard list-style append, as well as insert and extend methods.
Try implementing the __len__ and __delitem__ special methods for TypedList, as well as an append method.
17.9 Subclassing from built-in types
The previous example makes for a good exercise in understanding how to implement a list-like class from scratch, but it’s also a lot of work. In practice, if you were planning to implement your own list-like structure along the lines demonstrated here, you might instead consider subclassing the list type or the UserList type.
17.9.1 Subclassing list
Instead of creating a class for a typed list from scratch, as you did in the previous examples, you can subclass the list type and override all the methods that need to be aware of the allowed type. One big advantage of this approach is that your class has default versions of all list operations because it’s a list already. The main thing to keep in mind is that every type in Python is a class, and if you need a variation on the behavior of a built-in type, you may want to consider subclassing that type:
class TypedListList(list):
def __init__(self, example_element, initial_list=[]):
self.type = type(example_element)
if not isinstance(initial_list, list):
raise TypeError("Second argument of TypedList must "
"be a list.")
for element in initial_list:
self.__check(element)
super().__init__(initial_list)
def __check(self, element):
if type(element) != self.type:
raise TypeError("Attempted to add an element of "
"incorrect type to a typed list.")
def __setitem__(self, i, element):
self.__check(element)
super().__setitem__(i, element)
x = TypedListList("", 5 * [""])
x[2] = "Hello"
x[3] = "There"
print(x[2] + ' ' + x[3])Hello Therea, b, c, d, e = x
a, b, c, d('', '', 'Hello', 'There')x[:]['', '', 'Hello', 'There', '']del x[2]
x[:]['', '', 'There', '']x.sort()
x[:]['', '', '', 'There']Note that all that you need to do in this case is implement a method to check the type of items being added and then tweak __setitem__ to make that check before calling list’s regular __setitem__ method. Other methods, such as sort and del, work without any further coding. Overloading a built-in type can save a fair amount of time if you need only a few variations in its behavior, because the bulk of the class can be used unchanged.
17.9.2 Subclassing UserList
If you need a variation on a list (as in the previous examples), there’s a third alternative: you can subclass the UserList class, a list wrapper class found in the collections module. UserList was created for earlier versions of Python when subclassing the list type wasn’t possible, but it’s still useful, particularly for the current situation, because the underlying list is available as the data attribute:
from collections import UserList
class TypedUserList(UserList):
def __init__(self, example_element, initial_list=[]):
self.type = type(example_element)
if not isinstance(initial_list, list):
raise TypeError("Second argument of TypedList must "
"be a list.")
for element in initial_list:
self.__check(element)
super().__init__(initial_list)
def __check(self, element):
if type(element) != self.type:
raise TypeError("Attempted to add an element of "
"incorrect type to a typed list.")
def __setitem__(self, i, element):
self.__check(element)
self.data[i] = element
def __getitem__(self, i):
return self.data[i]
x = TypedUserList("", 5 * [""])
x[2] = "Hello"
x[3] = "There"
print(x[2] + ' ' + x[3])Hello Therea, b, c, d, e = x
a, b, c, d('', '', 'Hello', 'There')x[:]['', '', 'Hello', 'There', '']del x[2]
x[:]['', '', 'There', '']x.sort()
x[:]['', '', '', 'There']This example is much the same as subclassing list, except that in the implementation of the class, the list of items is available internally as the data member. In some situations, having direct access to the underlying data structure can be useful. Also, in addition to UserList, there are UserDict and UserString wrapper classes.
17.10 When to use special method attributes
As a rule, it’s a good idea to be somewhat cautious with the use of special method attributes. Other programmers who need to work with your code may wonder why one sequence-type object responds correctly to standard indexing notation whereas another doesn’t.
My general guidelines are to use special method attributes in either of two situations:
If I have a frequently used class in my own code that behaves in some respects like a Python built-in type, I’ll define such special method attributes as needed. This situation occurs most often with objects that behave like sequences in one way or another.
If I have a class that behaves identically or almost identically to a built-in class, I may choose to define all of the appropriate special function attributes or subclass the built-in Python type and distribute the class. An example of the latter solution might be lists implemented as balanced trees so that access is slower but insertion is faster than with standard lists.
These rules aren’t hard and fast. It’s often a good idea to define the __str__ special method attribute for a class, for example, so that you can say print(instance) in debugging code and get an informative, nice-looking representation of your object printed to the screen.
Suppose that you want a dictionary-like type that allows only strings as keys (maybe to make it work like a shelf object, as described in chapter 13). What options would you have for creating such a class? What would be the advantages and disadvantages of each option?
17.11 Creating a string-only key-value dictionary
The preceding quick check mentions creating a dictionary that only allows strings as keys. Let’s take that idea a step further and actually implement a dictionary that only allows strings for both keys and values. This sort of dictionary might be useful, for example, to cache URLs and web pages in a web application.
As mentioned in the discussion of lists earlier, you would have three possible approaches: write a class from scratch, inherit from the built-in dictionary, or inherit from UserDict. I would suggest, for the best combination of simplicity and functionality, that you inherit from the built-in dict type and override the __setitem__() method.
You should be warned, however, that dictionaries can also be created from a series of key-value tuples and from other dictionaries, bypassing __setitem__(). To handle this, you would need to override the __init__() method. Checking the type of the initial parameter and then checking both keys and values appropriately would be one way to do this, but it would be simpler to call the parent class’s __init__()method first and then write only the code to check self afterward. As a final task, add code to your class to override the __init__()method to enforce both keys and values are only strings.
17.11.1 Solving the problem with AI-generated code
The first thing to keep in mind is that the AI should be told which approach to take. Since the recommendation is to subclass dict, that should be specified in the prompt, and in fact asking for a subclass of dict makes the prompt simpler. The AI solution will also need to deal correctly with both the __setitem__() and the __init__() methods.
17.11.2 Solutions and discussion
As mentioned earlier, for a full solution you need to override both the __setitem__() and the __init__() methods to make sure that only strings are allowed as keys and values. This is very straightforward for __setitem__() but a bit trickier for __init__(), since there are two types of parameters that can be passed in: a sequence of key-value tuples and another dictionary.
The human solution
My solution is fairly simple, checking the types of the keys and values in the __setitem__() method and then checking self’s keys and values in __init__():
""" Create a dictionary that allows only strings for keys and values"""
class StringDict(dict):
def __setitem__(self, key, value):
if not isinstance(key, str):
raise TypeError('keys must be strings') # <-- Checking type
if not isinstance(value, str):
raise TypeError('values must be strings')
super().__setitem__(key, value)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
key_error = any(not isinstance(_, str) for _ in self.keys()) # <-- Checking types iterating over keys and values
if key_error:
raise TypeError('keys must be strings')
value_error = any(not isinstance(_, str) for _ in self.values()) # <-- Checking types iterating over keys and values
if value_error:
raise TypeError('values must be strings')In the __setitem__() method, the isinstance function is used to check the type, and a TypeError is raised with the appropriate message if either the key or the value is not a string. If they are both strings, the parent class’s method is called to add the item to self.
The __init__() method has to be a bit more complicated. Since this method might be passed either a sequence of key-value tuples or a dictionary, it could be a bit complicated to write code to check both types. It’s a bit simpler to first call the parent class’s __init__ method, which will add either type of value to the new self object and then check that object using its keys and values methods. We use a generator expression, which is similar to a list comprehension but more memory efficient. The any function will return True if any of the values in the generated series are not instances of str. The other feature of the generator expressions is the use of “_” as the expression variable, which is a common Python idiom, suggesting that semianonymous, throw-away nature of that variable.
It might seem a bit odd to be checking self, since that implies that the object is already created. In a way, the object has been created, but in fact, an exception in __ init__ will cause the object to be discarded.
The AI solutions
For Copilot, the prompt was simple:
Create a subclass of dictionary that allows only strings as both keys and values.
The plan created by Copilot was
- 1 Create a subclass of dict named StringDict.
- 2 Override the __setitem__ method to check if both the key and value are instances of str. If not, raise a TypeError.
- 3 Override the __init__ method to call the parent’s __init__ method and then check all keys and values in the dictionary. If any are not instances of str, raise a TypeError.
The following code was then suggested:
class StringDict(dict):
def __setitem__(self, key, value):
if not isinstance(key, str):
raise TypeError('keys must be strings')
if not isinstance(value, str):
raise TypeError('values must be strings')
super().__setitem__(key, value)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
for key, value in self.items():
if not isinstance(key, str):
raise TypeError('keys must be strings')
if not isinstance(value, str):
raise TypeError('values must be strings')The resemblance to the human solution is surprising, although in many spots there isn’t much opportunity for variation. The key difference is that in __init__ the suggested code uses simple for loops, raising the exception as soon as a nonstring value is encountered. On reflection, I have to admit that this is preferable to the human solution, which will iterate over the entire self object’s keys and values, while Copilot’s solution will stop at the first error. In most cases, this approach probably wouldn’t matter much, but if there were a lot of illegal types passed to __init__, it could be significantly more efficient.
Colaboratory required a bit more of a prompt. The first prompt was the same as for Copilot:
Create a subclass of dictionary that allows only strings as both keys and values.
This resulted in a class that only overrode __setitem__, which is not enough:
class StringDict(dict):
def __setitem__(self, key, value):
if not isinstance(key, str) or not isinstance(value, str):
raise TypeError("Both keys and values must be strings.")
super().__setitem__(key, value)The prompt was then expanded to
Create a subclass of dictionary that allows only strings as both keys and values, including when creating the instance.
This worked better, giving the following:

This code is compact and works just fine. It’s worth noting a couple differences in the approach from the Copilot version. First, the __init__ method creates a separate anonymous dictionary by calling dict with its arguments. This works, but if the initial arguments are quite large, it might be an inefficient use of memory, since that anonymous dictionary won’t be deleted until all of the items are added to self, which is the dictionary being initialized. Still, this would only be a problem with an enormous amount of data, since only the dictionary structure, not the items themselves, would be duplicate. This approach also does not check the values in __init__ but instead adds each item in a loop that calls __setitem__ each time, checking the values. The advantage of this is that the checking code is not duplicated.
It’s also worth mentioning that this code checks both the key and the value in a compound if statement. This is perfectly legal but wouldn’t be my choice, since the exception can’t specify whether the problem is with a key or a value and because compound if statements are a little bit harder for humans reading the code to parse. Overall, however, this solution would be fine.
While there were some differences in approach, the simplicity of subclassing an existing data structure means that in many ways the solutions to this problem were similar and would be simpler than either using UserDict or implementing dictionary functionality from scratch.
Summary
- Types/classes are just Python objects.
- Types can be assigned a variable and compared to other objects for equality.
- Python has the tools to check the type of objects as needed in your code.
- Duck typing, which relies on the behavior of objects rather than their type, can let you write more flexible code.
- Special method attributes have names beginning and ending with “__” (“dunder” methods) and can be overridden to change the behavior of user-created classes.
- Subclassing built-in classes can be used to create similar classes with customized behavior.
- Python’s use of duck typing, special method attributes, and subclassing makes it possible to construct and combine classes in a variety of ways.
18. Packages
This chapter covers
- Defining a package
- Creating a simple package
- Exploring a concrete example
- Using the __all__ attribute
- Using packages properly
Modules make reusing small chunks of code easy. The problem comes when the project grows and the code you want to reload outgrows, either physically or logically, what would fit into a single file. If having one giant module file is an unsatisfactory solution, having a host of little unconnected modules isn’t much better. The answer to this problem is to combine related modules into a package.
In this chapter, we discuss Python packages as structure of directories and files on disk.
Quite often people speak of a “package” that combines one or more Python modules or packages into a single distributable file that can be uploaded to a package repository like PyPI, which is mentioned in the next chapter. There is an ever-increasing array of options for creating such packages, and that process is beyond the scope of this book A good starting point for learning how to create distributable Python packages would be the Python Packaging User Guide, which can be found at https://packaging.python.org/en/latest.
18.1 What is a package?
A module is a file containing code. A module defines a group of usually related Python functions or other objects. The name of the module is derived from the name of the file.
When you understand modules, packages are easy, because a package is a directory containing code and possibly further subdirectories. A package contains a group of usually related code files (modules). The name of the package is derived from the name of the main package directory.
Packages are a natural extension of the module concept and are designed to handle very large projects. Just as modules group related functions, classes, and variables, packages group related modules.
18.2 A first example: mathproj
To see how packages might work in practice, consider a design layout for a type of project that by nature is very large: a generalized mathematics package along the lines of Mathematica, Maple, or MATLAB. Maple, for example, consists of thousands of files, and some sort of hierarchical structure is vital to keeping such a project ordered. Let’s call this project as a whole mathproj.
You can organize such a project in many ways, but a reasonable design splits the project into two parts: ui, consisting of the UI elements, and comp, the computational elements. Within comp, it may make sense to further segment the computational aspect into symbolic (real and complex symbolic computation, such as high school algebra) and numeric (real and complex numerical computation, such as numerical integration). Then it may make sense to have a constants.py file in both the symbolic and numeric parts of the project.
The constants.py file in the numeric part of the project defines pi as
pi = 3.141592whereas the constants.py file in the symbolic part of the project defines pi as
class PiClass:
def __str__(self):
return "PI"
pi = PiClass()This means that a name like pi can be used in (and imported from) two different files named constants.py, as shown in figure 18.1.
The symbolic constants.py file defines pi as an abstract Python object, the sole instance of the PiClass class. As the system is developed, various operations can be implemented in this class that return symbolic rather than numeric results.
There’s a natural mapping from this design structure to a directory structure. The top-level directory of the project, called mathproj, contains subdirectories ui and comp; comp in turn contains subdirectories symbolic and numeric; and each of symbolic and numeric contains its own constants.pi file.
Given this directory structure, and assuming that the root mathproj directory is installed somewhere in the Python search path, Python code both inside and outside the mathproj package can access the two variants of pi as mathproj.symbolic.constants .pi and mathproj.numeric.constants.pi. In other words, the Python name for an item in the package is a reflection of the directory pathname to the file containing that item.
That’s what packages are all about. They’re ways of organizing very large collections of Python code into coherent wholes, by allowing the code to be split among different files and directories and imposing a module/submodule naming scheme based on the directory structure of the package files. Unfortunately, packages aren’t this simple in practice because details intrude to make their use more complex than their theory. The practical aspects of packages are the basis for the remainder of this chapter.
18.3 Implementing the mathproj package
The rest of this chapter uses the example of the mathproj package to illustrate the inner workings of the package mechanism (see figure 18.2). Be careful to distinguish between a file that ends in .py and contains module code, and the module itself, which does not end in .py, inside the file. The files you’ll be using in your example package are shown in listings 18.1 through 18.6.
The file in the following listing is the __init__.py file for the main package, which prints a message to show it was loaded and sets the package’s __all__ property.
Listing 18.1 File mathproj/__init__.py
print("Hello from mathproj init")
__all__ = ['comp']
version = 1.03The file in the following listing is the __init__.py file for the comp subpackage, which prints a different message to show it was loaded and sets the subpackage’s __all__ property.
Listing 18.2 File mathproj/comp/__init__.py
__all__ = ['c1']
print("Hello from mathproj.comp init")The file in the following listing is the c1.py file of the main package, which sets the comp sub-package’s x property to 1.0.
Listing 18.3 File mathproj/comp/c1.py
x = 1.00The file in the following listing is the __init__.py file for the numeric subpackage, which just prints a message to show it was loaded.
Listing 18.4 File mathproj/comp/numeric/__init__.py
print("Hello from numeric init")The file in the following listing is the n1.py file of the numeric subpackage, which imports elements of the main package and the comp subpackage and defines the g() function.
Listing 18.5 File mathproj/comp/numeric/n1.py
from mathproj import version
from mathproj.comp import c1
from mathproj.comp.numeric.n2 import h
def g():
print("version is", version)
print(h())Finally, the file in the following listing is the n2.py file of the numeric subpackage, which defines the h() function.
Listing 18.6 File mathproj/comp/numeric/n2.py
def h():
return "Called function h in module n2"For the purposes of the examples in this chapter, if you are using the Colaboratory notebook, all you need to do is execute the setup cell to create the directories and files. If you are using another Python installation, you will have to create the mathproj directories and subdirectories and save the files to them. Then, ensure that the current working directory for Python is the directory containing mathproj when executing these examples.
In most of the examples in this book, it’s not necessary to start up a new Python shell for each example. You can usually execute the examples in a Python shell that you’ve used for previous examples and still get the results shown. This isn’t true for the examples in this chapter, however, because the Python namespace must be clean (unmodified by previous import statements) for the examples to work properly. If you do run the examples that follow, please ensure that you run each separate example in a new session. In Colaboratory, this requires using the Runtime menu and selecting Restart Session. In the notebook, there will be comments at the beginning of cells that require a new session.
18.3.1 __init__.py files in packages
You’ll have noticed that all the directories in your package—mathproj, mathproj/comp, and mathproj/numeric—contain a file called __init__.py. An __init__.py file serves two purposes:
- Python recognizes a directory containing an __init__.py file as a package. This is optional but prevents directories containing miscellaneous Python code from being accidentally imported as though they defined a package.
- The __init__.py file is automatically executed by Python the first time a package or subpackage is loaded. This execution permits whatever package initialization you desire.
The first point is usually more important. For many packages, you won’t need to put anything in the package’s __init__.py file; just make sure that an empty __init__.py file is present.
18.3.2 Basic use of the mathproj package
Before getting into the details of packages, look at accessing items contained in the mathproj package. Start a new Python shell, and do the following:
import mathproj
#> Hello from mathproj initIf all goes well, you should get another input prompt and no error messages. Also, the message “Hello from mathproj init” should be printed to the screen by code in the mathproj/__init__.py file. I will talk more about __init__.py files soon; for now, all you need to know is that the files run automatically whenever a package is first loaded.
The mathproj/__init__.py file assigns 1.03 to the variable version. version is in the scope of the mathproj package namespace, and after it’s created, you can see it via mathproj, even from outside the mathproj/__init__.py file:
mathproj.version
#> 1.03In use, packages can look a lot like modules; they can provide access to objects defined within them via attributes. This fact isn’t surprising, because packages are a generalization of modules.
18.3.3 Loading subpackages and submodules
Now start looking at how the various files defined in the mathproj package interact with one another. To do so, invoke the function g defined in the file mathproj/comp/ numeric/n1.py. The first obvious question is whether this module has been loaded. You’ve already loaded mathproj, but what about its subpackage? To see whether it’s known to Python, type
mathproj.comp.numeric.n1
#> Traceback (most recent call last):
#> File "<stdin>", line 1, in <module>
#> AttributeError: module 'mathproj' has no attribute 'n1'In other words, loading the top-level module of a package isn’t enough to load all the submodules, which is in keeping with Python’s philosophy that it shouldn’t do things behind your back. Clarity is more important than conciseness.
This restriction is simple enough to overcome. You import the module of interest and then execute the function g in that module:
import mathproj.comp.numeric.n1
#> Hello from mathproj.comp init
#> Hello from numeric init
mathproj.comp.numeric.n1.g()
#> version is 1.03
#> Called function h in module n2Notice, however, that the lines beginning with Hello are printed out as a side effect of loading mathproj.comp.numeric.n1. These two lines are printed out by print statements in the __init__.py files in mathproj/comp and mathproj/comp/numeric. In other words, before Python can import mathproj.comp.numeric.n1, it has to import mathproj.comp and then mathproj.comp.numeric. Whenever a package is first imported, its associated __init__.py file is executed, resulting in the Hello lines. To confirm that both mathproj.comp and mathproj.comp.numeric are imported as part of the process of importing mathproj.comp.numeric.n1, you can check to see that mathproj.comp and mathproj.comp.numeric are now known to the Python session:
mathproj.comp
#> <module 'mathproj.comp' from 'mathproj/comp/__init__.py'>
mathproj.comp.numeric
#> <module 'mathproj.comp.numeric' from 'mathproj/comp/numeric/__init__.py'>18.3.4 import statements within packages
Files within a package don’t automatically have access to objects defined in other files in the same package. As in outside modules, you must use import statements to explicitly access objects from other package files. To see how this use of import works in practice, look back at the n1 subpackage. The code contained in n1.py is
from mathproj import version
from mathproj.comp import c1
from mathproj.comp.numeric.n2 import h
def g():
print("version is", version)
print(h())g makes use of both version from the top-level mathproj package and the function h from the n2 module; hence, the module containing g must import both version and h to make them accessible. You import version as you would in an import statement from outside the mathproj package: by saying from mathproj import version. In this example, you explicitly import h into the code by saying from mathproj.comp .numeric.n2 import h, and this technique works in any file; explicit imports of package files are always allowed. But because n2.py is in the same directory as n1.py, you can also use a relative import by prepending a single dot to the submodule name. In other words, you can say
from .n2 import has the third line in n1.py, and it works fine.
You can add more dots to move up more levels in the package hierarchy, and you can add module names. Instead of writing
from mathproj import version
from mathproj.comp import c1
from mathproj.comp.numeric.n2 import hyou could have written the imports of n1.py as
from ... import version
from .. import c1
from .n2 import hRelative imports can be handy and quick to type, but be aware that they’re relative to the module’s __name__ property. Therefore, any module being executed as the main module and thus having __main__ as its __name__ can’t use relative imports.
18.4 The __all__ attribute
If you look back at the various __init__.py files defined in mathproj, you’ll notice that some of them define an attribute called __all__. This attribute has to do with execution of statements of the form from … import *, and it requires explanation.
Generally speaking, you’d hope that if outside code executed the statement from mathproj import *, it would import all nonprivate names from mathproj. In practice, life is more difficult. The primary problem is that some operating systems have an ambiguous definition of case when it comes to filenames. Because objects in packages can be defined by files or directories, this situation leads to ambiguity as to the exact name under which a subpackage might be imported. If you say from mathproj import *, will comp be imported as comp, Comp, or COMP? If you were to rely only on the name as reported by the operating system, the results might be unpredictable.
There’s no good solution to this problem, which is an inherent one caused by poor OS design. As the best possible fix, the __all__ attribute was introduced. If present in an __init__.py file, __all__ should give a list of strings, defining those names that are to be imported when a from … import * is executed on that particular package. If __all__ isn’t present, from … import * on the given package does nothing. Because case in a text file is always meaningful, the names under which objects are imported aren’t ambiguous, and if the operating system thinks that comp is the same as COMP, that’s its problem.
Use the Runtime menu and restart your session again; then try the following:
from mathproj import *Hello from mathproj init
Hello from mathproj.comp initThe __all__ attribute in mathproj/__init__.py contains a single entry, comp, and the import statement imports only comp. It’s easy enough to check whether comp is now known to the Python session:
comp
#> <module 'mathproj.comp' from 'mathproj/comp/__init__.py'>But note that there’s no recursive importing of names with a from … import * statement. The __all__ attribute for the comp package contains c1, but c1 isn’t magically loaded by your from mathproj import * statement:
c1
#> Traceback (most recent call last):
#> File "<stdin>", line 1, in <module>
#> NameError: name 'c1' is not definedTo insert names from mathproj.comp, you must again do an explicit import:
from mathproj.comp import c1
c1
#> <module 'mathproj.comp.c1' from 'mathproj/comp/c1.py'>18.5 Proper use of packages
Most of your packages shouldn’t be as structurally complex as these examples imply. The package mechanism allows wide latitude in the complexity and nesting of your package design. It’s obvious that very complex packages can be built, but it isn’t obvious that they should be built.
The following are a couple of suggestions that are appropriate in most circumstances:
- Packages shouldn’t use deeply nested directory structures. Except for absolutely huge collections of code, there should be no need for them. For most packages, a single top-level directory is all that’s needed. A two-level hierarchy should be able to effectively handle all but a few of the rest. As written in The Zen of Python (see the appendix), “Flat is better than nested.”
- Although you can use the __all__ attribute to hide names from from … import* by not listing those names, doing so probably is not a good idea, because it’s inconsistent. If you want to keep an element from loading when everything is imported, you can do so by prefacing it with an underscore, as mentioned in chapter 10 on modules.
Suppose that you’re writing a package that takes a URL, retrieves all images on the page pointed to by that URL, resizes them to a standard size, and stores them.
Leaving aside the exact details of how each of these functions will be coded, how would you organize those features into a package?
18.6 Creating a package
In chapter 14, you added error handling to the text-cleaning and word-frequencycounting module that you created in chapter 10. Refactor that code into a package containing at least one module for the cleaning functions, another for the processing functions, and (optionally) one for custom exceptions (if you have any). Then write a simple main function that uses all the modules in the package.
18.6.1 Solving the problem with AI-generated code
The main concern in this lab is deciding what to put in each function. This is obviously something where there might be room for different interpretations, so we’ll accept any division that is not obviously wrong.
18.6.2 Solutions and discussion
As you may recall, back in chapter 10 we created a module of functions to clean a text (part of the first chapter of Moby Dick) and count the occurrences of each word. While that module was small enough to be manageable, it wasn’t the best design, since there was no separation of different types of functions—functionality for cleaning the data, for counting the words, and for custom exceptions were all in the same module.
Using a package lets us separate those different types of functionality into their own modules (or even subpackages, for something larger). This can make using and maintaining that code easier.
The human solution
I create a package word_count by refactoring the module of functions created in chapter 10 into a package with three modules. The first file is __init__.py, which imports the custom exception from exceptions.py, the clean_line and get_words data cleaning functions from cleaning.py, and the count_words and word_stats functions from counter.py. Importing those elements into the main package namespace means that the user won’t need to worry about specifying the module—they will appear in the top level of the package.
Listing 18.7 __init__.py
#__init__.py
from word_count.exceptions import EmptyStringError
from word_count.cleaning import clean_line, get_words
from word_count.counter import count_words, word_stats The second file is exceptions.py, which contains the custom exception. While not always necessary, it’s often a good idea to have custom exceptions in a separate file, where they can be imported as needed.
Listing 18.8 exceptions.py
# exceptions.py
class EmptyStringError(Exception):
passThe third file is cleaning.py, which holds the code concerned with cleaning the data. Note that it imports the custom exception.
Listing 18.9 cleaning.py
# cleaning.py
from word_count.exceptions import EmptyStringError
punct = str.maketrans("", "", "!.,:;-?")
def clean_line(line):
"""changes case and removes punctuation"""
# raise exception if line is empty
# uncomment to test EmptyStringError
# if not line.strip():
# raise EmptyStringError()
# make all one case
cleaned_line = line.lower()
# remove punctuation
cleaned_line = cleaned_line.translate(punct)
return cleaned_line
def get_words(line):
"""splits line into words, and rejoins with newlines"""
words = line.split()
return "\n".join(words) + "\n"The final file is counter.py, which has the code for actually counting the words and compiling the stats. Note that this module now operates independently of the other modules, simply taking a list of words and a dictionary of word counts.
Listing 18.10 counter.py
# counter.py
def count_words(words):
"""takes list of cleaned words, returns count dictionary"""
word_count = {}
for word in words:
try:
count = word_count.setdefault(word, 0)
except TypeError:
# if 'word' is not hashable, skip to next word.
pass
word_count[word] += 1
return word_count
def word_stats(word_count):
"""Takes word count dictionary, returns top and bottom five entries"""
word_list = list(word_count.items())
word_list.sort(key=lambda x: x[1])
try:
least_common = word_list[:5]
most_common = word_list[-1:-6:-1]
except IndexError as e:
# if list is empty or too short, just return list
least_common = word_list
most_common = list(reversed(word_list))
return most_common, least_commonThese functions are the same as those used in the solution to the lab for chapter 10 but now split into three modules, with an __init__.py file to load various functions on import.
The test code is also very similar to that of the solution for the lab in chapter 10 but with the imports changed to use the package. The main difference is now it imports the package and then uses the relevant items from the package to clean the data and create a word count:
import word_count
if __name__ == "__main__":
with (open("moby_01.txt") as infile,
open("moby_01_clean.txt", "w") as outfile):
for line in infile:
cleaned_line = word_count.clean_line(line)
cleaned_words = word_count.get_words(cleaned_line)
# write all words for line
outfile.write(cleaned_words)
moby_words = []
with open('moby_01_clean.txt') as infile:
for word in infile:
if word.strip():
moby_words.append(word.strip())
word_counter = word_count.count_words(moby_words)
most, least = word_count.word_stats(word_counter)
print("Most common words:")
for word in most:
print(word)
print("\nLeast common words:")
for word in least:
print(word)This code will work in a file that is in a directory containing the word_count package directory, or in a cell in Colaboratory, or if the word_count package directory is otherwise on the Python search path.
The AI solutions
The Copilot solution was disappointing. The prompt given to Copilot, while in the same directory as the files from chapter 10’s lab, was
Refactor the code in word_processing.py into a package containing at least one module for the cleaning functions, and another for the processing functions, and (optionally) one for custom exceptions (if you have any). The refactor main.py to use the new package.
The plan it created was
- 1 Create a package directory named word_processing.
- 2 Inside word_processing, create three modules: cleaning.py, processing.py, and exceptions.py.
- 3 Move the cleaning functions to cleaning.py.
- 4 Move the processing functions to processing.py.
- 5 If there are any custom exceptions, move them to exceptions.py.
- 6 In main.py, import the necessary functions from the word_processing package and use them.
word_processing/cleaning.py
import re
def clean_line(line):
# Remove punctuation and convert to lowercase
line = re.sub(r'[^\w\s]', '', line)
line = line.lower()
return lineword_processing/cleaning.py
def count_word_occurrences(words):
word_counts = {}
for word in words:
if word in word_counts:
word_counts[word] += 1
else:
word_counts[word] = 1
return word_counts
def print_common_words(word_counts, n):
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
print(f"{n} most common words:")
for word, count in sorted_word_counts[:n]:
print(f"{word}: {count}")
def print_least_common_words(word_counts, n):
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
print(f"{n} least common words:")
for word, count in sorted_word_counts[-n:]:
print(f"{word}: {count}")
def write_words_to_file(words, output_file):
for word in words:
output_file.write(word + '\n')
def process_file(input_file_path, output_file_path):
with open(input_file_path, 'r') as input_file:
with open(output_file_path, 'w') as output_file:
for line in input_file:
cleaned_line = clean_line(line)
words = cleaned_line.split()
write_words_to_file(words, output_file)word_processing/exceptions.py
# If you have any custom exceptions, define them hereSince custom exceptions were optional, it is fine that none were created. Finally, we have a main file that imports the functions from the processing module.
word_processing/__init__.py
from .cleaning import clean_line
from .processing import (
count_word_occurrences,
print_common_words,
print_least_common_words,
write_words_to_file,
process_file
)main.py
from word_processing import (
process_file,
count_word_occurrences,
print_common_words,
print_least_common_words
)
# Example usage
input_file_path = 'input.txt'
output_file_path = 'output.txt'
process_file(input_file_path, output_file_path)
# Assuming you have a list of words from somewhere
words = ["example", "words", "for", "testing", "example", "words"]
word_counts = count_word_occurrences(words)
print_common_words(word_counts, 3)
print_least_common_words(word_counts, 3)This lab required almost no new code. Instead, the problem demanded a knowledge of the structure of Python packages and the ability to select and move the correct elements of existing code to the appropriate places in the new package. While this would strike most experienced human coders as straightforward, it proved to be quite a challenge for the AI bots. Both bots produced elements that were useful, but neither produced a fully usable solution on their own. While tweaking the prompts can improve this situation, it’s also wise to keep in mind the time tradeoff between fiddling with the AI prompt versus writing your code. This is especially worth keeping in mind using AI tools to tackle higher-level problems.
Summary
- Packages let you create libraries of code that span multiple files and directories.
- Using packages allows better organization of large collections of code than single modules would permit.
- An __init__.py causes its folder to be recognized by Python as a package and is executed when the package is imported.
- Subpackages need to be explicitly imported, either in your code or in the package __init__py.
- You should be wary of nesting directories in your packages more than one or two levels deep unless you have a very large and complex library.
- The __all__ attribute can be used to hide elements from a wildcard import, but it’s better to explicitly exclude them by beginning their names with a “_”.
19. Using Python libraries
This chapter covers
- Managing various data types—strings, numbers, and more
- Manipulating files and storage
- Accessing operating system services
- Using internet protocols and formats
- Developing and debugging tools
- Accessing the Python Package Index
- Installing Python libraries and virtual environments using pip and venv
Python has long proclaimed that one of its key advantages is its “batteries included” philosophy. This means that a stock install of Python comes with a rich standard library that lets you handle a wide variety of situations without the need to install additional libraries. This chapter gives you a high-level survey of some of the contents of the standard library, as well as some suggestions on finding and installing external modules. Since the content is purely informational, this chapter doesn’t include a lab or other exercises.
19.1 “Batteries included”: The standard library
In Python, what’s considered to be the library consists of several components, including built-in data types and constants that can be used without an import statement, such as numbers and lists, as well as some built-in functions and exceptions. The largest part of the library is an extensive collection of modules. If you have Python, you also have libraries to manipulate diverse types of data and files to interact with your operating system, to write servers and clients for many internet protocols, and to develop and debug your code.
What follows is a survey of the high points. Although many of the major modules are mentioned, for the most complete and current information, I recommend that you spend time on your own exploring the library reference that’s part of the Python documentation. In particular, before you go in search of an external library, be sure to scan through what Python already offers. You may be surprised by what you find.
19.1.1 Managing various data types
The standard library naturally contains support for Python’s built-in types, which I touch on in this section. In addition, three categories in the standard library deal with various data types: string services, data types, and numeric modules.
String services include the modules in table 19.1 that deal with bytes as well as strings. The three main things these modules deal with are strings and text, sequences of bytes, and Unicode operations.
| Module | Description and possible uses |
|---|---|
string |
Compare with string constants, such as digitsor whitespace; format strings (see chapter 6) |
re |
Search and replace text using regular expressions (see chapter 16) |
struct |
Interpret bytes as packed binary data and read and write structured data to/from files |
difflib |
Use helpers for computing deltas, find differences between strings or sequences, and create patches and diff files |
textwrap |
Wrap and fill text and format text by breaking lines or adding spaces |
The data types category is a diverse collection of modules covering various data types, particularly, time, date, and collections, as shown in table 19.2.
| Module | Description and possible uses |
|---|---|
datetime, calendar |
Date, time, and calendar operations |
collections |
Container data types |
enum |
Allows creation of enumerator classes that bind symbolic names to constant values |
array |
Efficient arrays of numeric values |
sched |
Event scheduler |
queue |
Synchronized queue class |
copy |
Shallow and deep copy operations |
pprint |
Data pretty printer |
typing |
Support for annotating code with hints as to the types of objects, particularly of function parameters and return values |
As the name indicates, the numeric and mathematical modules deal with numbers and mathematical operations, and the most common of these modules are listed in table 19.3. These modules have everything you need to create your own numeric types and handle a wide range of math operations.
| Module | Description and possible uses |
|---|---|
numbers |
Numeric abstract base classes |
math, cmath |
Mathematical functions for real and complex numbers |
decimal |
Decimal fixed-point and floating-point arithmetic |
statistics |
Functions for calculating mathematical statistics |
fractions |
Rational numbers |
random |
Generate pseudorandom numbers and choices and shuffle sequences |
itertools |
Functions that create iterators for efficient looping |
functools |
Higher-order functions and operations on callable objects |
operator |
Standard operators as functions |
19.1.2 Manipulating files and storage
Another broad category in the standard library covers files, storage, and data persistence and is summarized in table 19.4. This category ranges from modules for file access to modules for data persistence and compression and handling special file formats.
| Module | Description and possible uses |
|---|---|
os.path |
Perform common pathname manipulations |
pathlib |
Deal with pathnames in an object-oriented way |
fileinput |
Iterate over lines from multiple input streams |
filecmp |
Compare files and directories |
tempfile |
Generate temporary files and directories |
glob, fnmatch |
Use UNIX-style pathname and filename pattern handling |
linecache |
Gain random access to text lines |
shutil |
Perform high-level file operations |
pickle, shelve |
Enable Python object serialization and persistence |
sqlite3 |
Work with a DB-API 2.0 interface for SQLite databases |
zlib, gzip, bz2, zipfile, tarfile |
Work with archive files and compressions |
csv |
Read and write CSV files |
configparser |
Use a configuration file parser; read/write Windows-style configuration .ini files |
19.1.3 Accessing operating system services
This category is another broad one, containing modules for dealing with your operating system. As shown in table 19.5, this category includes tools for handling command-line parameters, redirecting file and print output and input, writing to log files, running multiple threads or processes, and loading non-Python (usually, C) libraries for use in Python.
| Module | Description |
|---|---|
os |
Miscellaneous operating system interfaces |
io |
Core tools for working with streams |
time |
Time access and conversions |
optparse |
Powerful command-line option parser |
logging |
Logging facility for Python |
getpass |
Portable password input |
curses |
Terminal handling for character-cell displays |
platform |
Access to underlying platform’s identifying data |
ctypes |
Foreign function library for Python |
select |
Waiting for I/O completion |
threading |
Higher-level threading interface |
multiprocessing |
Process-based threading interface |
subprocess |
Subprocess management |
19.1.4 Using internet protocols and formats
The internet protocols and formats category is concerned with encoding and decoding the many standard formats used for data exchange on the internet, from MIME and other encodings to JSON and XML. This category also has modules for writing servers and clients for common services, particularly HTTP, and a generic socket server for writing servers for custom services. The most commonly used modules are listed in table 19.6.
| Module | Description |
|---|---|
socket, ssl |
Low-level networking interface and SSL wrapper for socket objects |
Email |
Email and MIME handling package |
Json |
JSON encoder and decoder |
Mailbox |
Manipulate mailboxes in various formats |
Mimetypes |
Map filenames to MIME types |
base64, binhex, binascii, quopri, uu |
Encode/decode files or streams with various encodings |
html.parser, html.entities |
Parse HTML and XHTML |
xml.parsers.expat, xml.dom, xml.sax, xml.etree.ElementTree |
Various parsers and tools for XML |
cgi, cgitb |
Common Gateway Interface support |
Wsgiref |
WSGI utilities and reference implementation |
urllib.request, urllib.parse |
Open and parse URLs |
ftplib, poplib, imaplib, nntplib, smtplib, telnetlib |
Clients for various internet protocols |
Socketserver |
Framework for network servers |
http.server |
HTTP servers |
xmlrpc.client, xmlrpc.server |
XML-RPC client and server |
19.1.5 Development and debugging tools and runtime services
Python has several modules to help you debug, test, modify, and otherwise interact with your Python code at runtime. As shown in table 19.7, this category includes two testing tools, profilers, modules to interact with error tracebacks, the interpreter’s garbage collection, and so on, as well as modules that let you tweak the importing of other modules.
| Module | Description |
|---|---|
Pydoc |
Documentation generator and online help system |
Doctest |
Test interactive Python examples |
Unittest |
Unit testing framework |
test.support |
Utility functions for tests |
Pdb |
Python debugger |
profile, cProfile |
Python profilers |
Timeit |
Measure execution time of small code snippets |
trace |
Trace or track Python statement execution |
sys |
System-specific parameters and functions |
atexit |
Exit handlers |
__future__ |
Future statement definitions—features to be added to Python |
gc |
Garbage collector interface |
inspect |
Inspect live objects |
imp |
Access the import internals |
zipimport |
Import modules from zip archives |
modulefinder |
Find modules used by a script |
19.2 Moving beyond the standard library
Although Python’s “batteries included” philosophy and well-stocked standard library mean that you can do a lot with Python out of the box, there will inevitably come a situation in which you need some functionality that doesn’t come with Python. This section surveys your options when you need to do something that isn’t in the standard library.
19.3 Adding more Python libraries
Finding a Python package or module can be as easy as entering the functionality you’re looking for (such as mp3 tags and Python) in a search engine and then sorting through the results. While using this approach casts the widest possible net, keep in mind that not all sources are equally reliable and trustworthy. Ultimately, you are the one responsible for the security and functionality of the software you run on your systems, so be sure to consider the source and quality of the code before trusting it.
In some cases, your search may turn up the module you need packaged for your OS—with an executable Windows or macOS installer or a package for your Linux distribution. This technique can be one of the easiest ways to add a library to your Python installation, because the installer or your package manager takes care of all the dependencies and details of adding the module to your system correctly. It can also be the answer for installing more complex libraries, such as scientific libraries with complex build requirements and dependencies.
On the other hand, except for scientific libraries, such prebuilt packages aren’t the rule for Python software. Such packages tend to be a bit older, which may cause version problems with newer packages, and they offer less flexibility in where and how they’re installed.
19.4 The Python Package Index
Although source packages get the job done, there’s one catch: you have to find the correct package, which can be a chore. And when you’ve found a package, you don’t always know if the repository is secure and the package is safe. In short, it would be nice to have a reasonably reliable and easy-to-search source from which to download that package.
To meet this need, various Python package repositories have been made available over the years. Currently, the official (but by no means the only) repository for Python code is the Python Package Index (PyPI) linked from the Python.org website. You can access it from a link on the main page or directly at https://pypi.python.org. PyPI contains packages for various Python versions from over 604,000 projects, listed by date and name but also searchable and broken down by category, Python version, and more.
PyPI is the logical next stop if you can’t find the functionality you want with a search of the standard library.
19.5 Installing Python libraries using pip and venv
If you need a third-party package that isn’t prepackaged for your platform, you’ll have to turn to a more native Python package. This fact presents a couple of problems:
- To install the module, you must find and download it.
- Installing even a single Python module correctly can involve a certain amount of hassle in dealing with Python’s paths and your system’s permissions, which makes a standard installation system helpful.
If you are using Colaboratory, there is some good news—you will probably not have to worry about the processes described in the rest of this section. Colaboratory comes with the most common additional libraries already installed, and since each session is its own temporary environment, you don’t need to worry about managing virtual environments.
The rest of this section will be of more use if you are managing your own Python installation and environments.
Python offers pip as the current standard solution to both problems. pip tries to find the module in the Python Package Index, downloads it and any dependencies, and takes care of the installation. The basic syntax of pip is quite simple. To install the popular requests library from the command line, for example, all you have to do is type
$ python3 -m pip install requestsUpgrading to the library’s latest version requires only the addition of the –-upgrade switch:
$ python3 -m pip install –-upgrade requestsFinally, if you need to specify a particular version of a package, you can append it to the name as follows:
$ python3 -m pip install requests==2.32.3
$ python3 -m pip install requests>=2.32Note that if you are using Colaboratory, most of the commonly used packages (including requests) are already installed, but you can install other packages with the previous commands, prefixed with a !:
! python3 -m pip install requestsMany distributions of Python include pip, but some Linux distributions (e.g., Debianor Ubuntu-based distros) have split pip into its own package that needs to be installed separately.
19.5.1 Installing with the –user flag
On many occasions, you can’t or don’t want to install a Python package in the main system instance of Python. Maybe you need a bleeding-edge version of the library, but some other application (or the system itself) still uses an older version. Or maybe you don’t have access privileges to modify the system’s default Python. In cases like those, one answer is to install the library with the –-user flag. This flag installs the library in the user’s home directory, where it’s not accessible by any other users. To install requests for only the local user, type
$ python -m pip install --user requestsAs I mentioned previously, this scheme is particularly useful if you’re working on a system on which you don’t have sufficient administrator rights to install software or if you want to install a different version of a module. If your needs go beyond the basic installation methods discussed here, a good place to start is “Installing Python Modules,” which you can find in the Python documentation.
19.5.2 Virtual environments
You have another, better option if you need to avoid installing libraries in the system Python. This option is called a virtual environment (virtualenv). A virtual environment is a self-contained directory structure that contains both an installation of Python and its additional packages. Because the entire Python environment is contained in the virtual environment, the libraries and modules installed there can’t conflict with those in the main system or in other virtual environments, allowing different applications to use different versions on both Python and its packages.
Creating and using a virtual environment takes two steps. First, you create the environment:
myuser@mymachine\$ python -m venv test-envThis step creates the environment with Python and pip installed in a directory called test-env. Then, when the environment is created, you activate it. On Windows, you do the following:
# The Windows prompt shows the current directory (user’s home directory).
C:\Users\myuser> test-env\Scripts\activate.batOn Unix or macOS systems, you can use source or . to activate the environment:
# username@machinename is the common prompt string on linux/Unix systems.
myuser@mymachine\$ source test-env/bin/activateWhen you’ve activated the environment, you can use pip to manage packages as earlier, but in the virtual environment, pip is a standalone command:
# Once activated, the environment name is prepended to the prompt.
(test-env) myuser@mymachine\$ pip install requestsIn addition, whatever version of Python you used to create the environment will be the default Python for that environment and will be used every time you activate that environment.
Virtual environments are very useful for managing projects and their dependencies and are very much a standard practice, particularly for developers working on multiple projects. For more information, look at the “Virtual Environments and Packages” section of the Python tutorial in the Python online documentation.
19.5.3 Other options
For managing both packages and virtual environments, there are a number of other options, and as work continues in this area, I would expect even more choices by the time this book is in print. At the time of writing, I was using Pyenv both to manage virtual environments and for installations of different versions of Python.
Various other systems have come along to do the same tasks that pip performs, including poetry, rye, and uv, as well as others. The advantage of pip and venv is that they are the current standard with Python. As you gain experience and a have a better sense of your requirements, you may want to explore the other tools.
There is another common distribution of Python—Anaconda—which is quite popular for scientific computing and data science. It has its own package management tool, called conda, which is good at handling complex dependencies. The Anaconda ecosystem of packages is not as extensive as the one supported by PyPI, with around 8,000 packages available. The plus side is the focus on packages used by data science and related fields.
Summary
- Python has a rich standard library that covers more common situations than many other languages, and you should check what’s in the standard library carefully before looking for external modules.
- Among other things, the standard library has modules for handling different data types, manipulating files and filesystems, accessing operating system services, handing internet protocols, and developing and debugging Python code.
- If you do need an external module, prebuilt packages for your operating system are the easiest option, but they’re sometimes older and often hard to find.
- The standard way to install from source is to use pip, and the best way to prevent conflicts among multiple projects is to create virtual environments with the venv module.
- Usually, the logical first step in searching for external modules is the PyPI.